An architecture integrating DuckDB with Postgres for Vector databasing is presented using the newly added DuckDB Array type and related functions. The goal of the architecture is to separate business applications from analytical applications, but without a loss in consistency or large latencies. I want to show how to integrate different tools to bridge the gap between business and data applications with their respective OLTP and OLAP databases.
Vector embeddings of digital assets
Digital assets such as images, text, audio, and video can be fed to AI models as sequences of numbers. Their RAW representation might not be the most effective to feed into AI models. The models might be sensitive to the noise the RAW representation and miss the relationships and objects within the digital asset. Embedding AI models are optimized to create representations of their input based on a reference vector space. This reference vector space is trained on large datasets and allows for reduction of dimensionality and thus storage space. The resulting vector embedding codifies the objects and their context of relationships with other objects and their relationships to other objects in the domain. Embeddings generated by a specific embedding model have a fixed number of dimensions represented as an array of floating-point numbers.
Vector Databases
Vector Databases are a bit of a Hype but have become important in most LLM applications that rely heavily on vector embeddings for retrieval of context in response to prompts. They allow storage of high dimensional vectors and provide methods to retrieve the top-N similar vectors based on an input vector. Vector indexing is applied to speed up such retrievals.
Retrieval Augmented Generation (RAG)
An essential step in the preprocessing before querying the LLM is the retrieval of context that has a strong similarity to the prompt submitted by the user. Retrieval of contextual information based on similarity is the strength of the Vector database or any similar system. Here, I use context available in business applications with low latency to ensure that models are referring to the latest available information moderated by the contributors. Below part of the RAG flow is shown. The relevant part for this blog is the retrieval of the similar content from the vector database by providing the embedded representation of the user’s prompt. The vector database contains up-to-date domain knowledge that was not available during original training of the LLM nor during later finetuning of the LLM. In this blog I select domain specific knowledge to be written to the vector database from a larger set of available information to reduce the noise in the retrieval process based on similarity to the prompt.
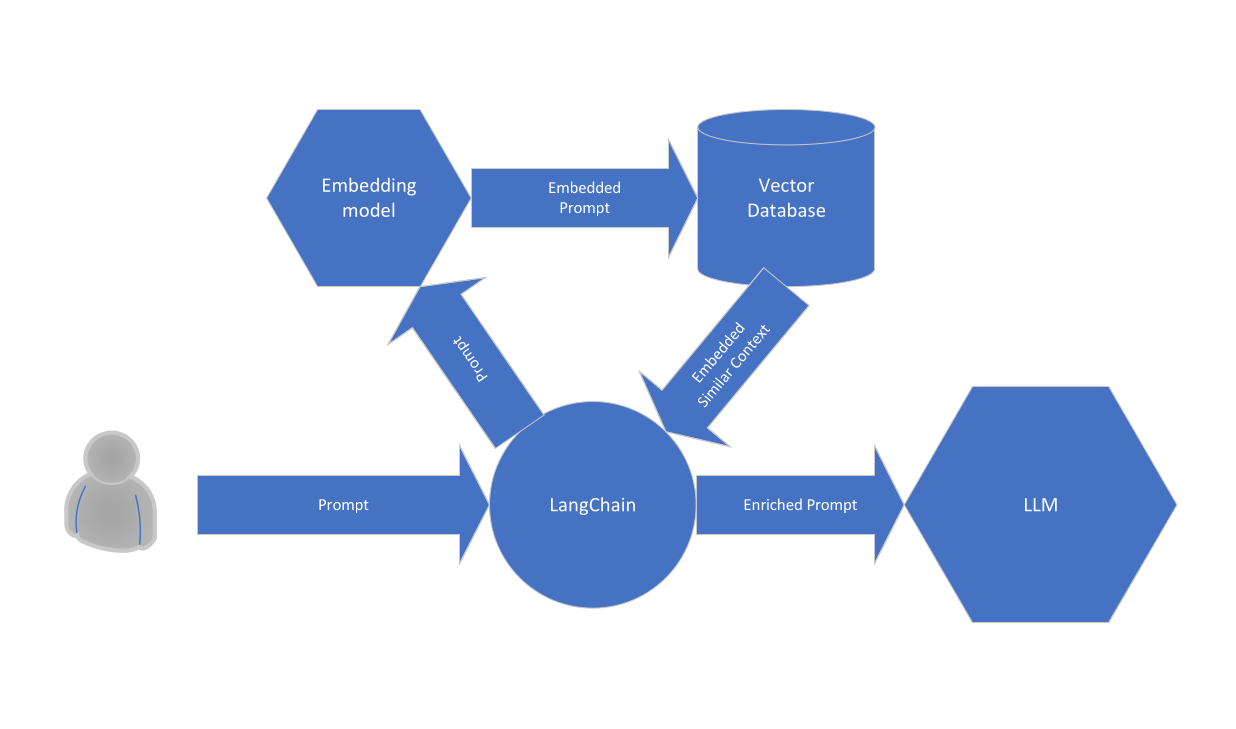
Our LLM derived vector databasing use case
An internal wiki (f.i. Confluence) contains all the information that an organisation builds over time. During the day new pages are created and updates to existing pages are made. These changes are monitored by an embedding generator that computes the embedding of the newly created and updated pages and Upserts them into Postgres (PGVector database). The OLTP mechanisms allow for reliable mirroring of the state of the wiki. Our LLM applications want to use the information of the wiki, but I would like to scope the context to specific knowledge domains. The embeddings that define the knowledge domains are kept in parquet files stored in the data platform. The vectors stored in Parquet define a knowledge domain that I want to filter on for a certain use case. The goal is reduce the noise in the results when querying the vector database on similarity to the user’s prompt, by preselecting specific knowledge domains from the internal wiki. To integrate between the business application (Postgres) and the data platform (parquet files) I choose DuckDB. Besides being a great data integration tool, DuckDB has also shown to speed up analytical work in comparison of running analytical queries straight on Postgres (Querying Postgres Tables Directly From DuckDB - DuckDB). An earlier blog explores similar integrations of PGVector and DuckDB (Vector similarity search with duckdb | by Chang She). I would like to extend this approach with the new DuckDB Array Type and the context of our proposed use case.
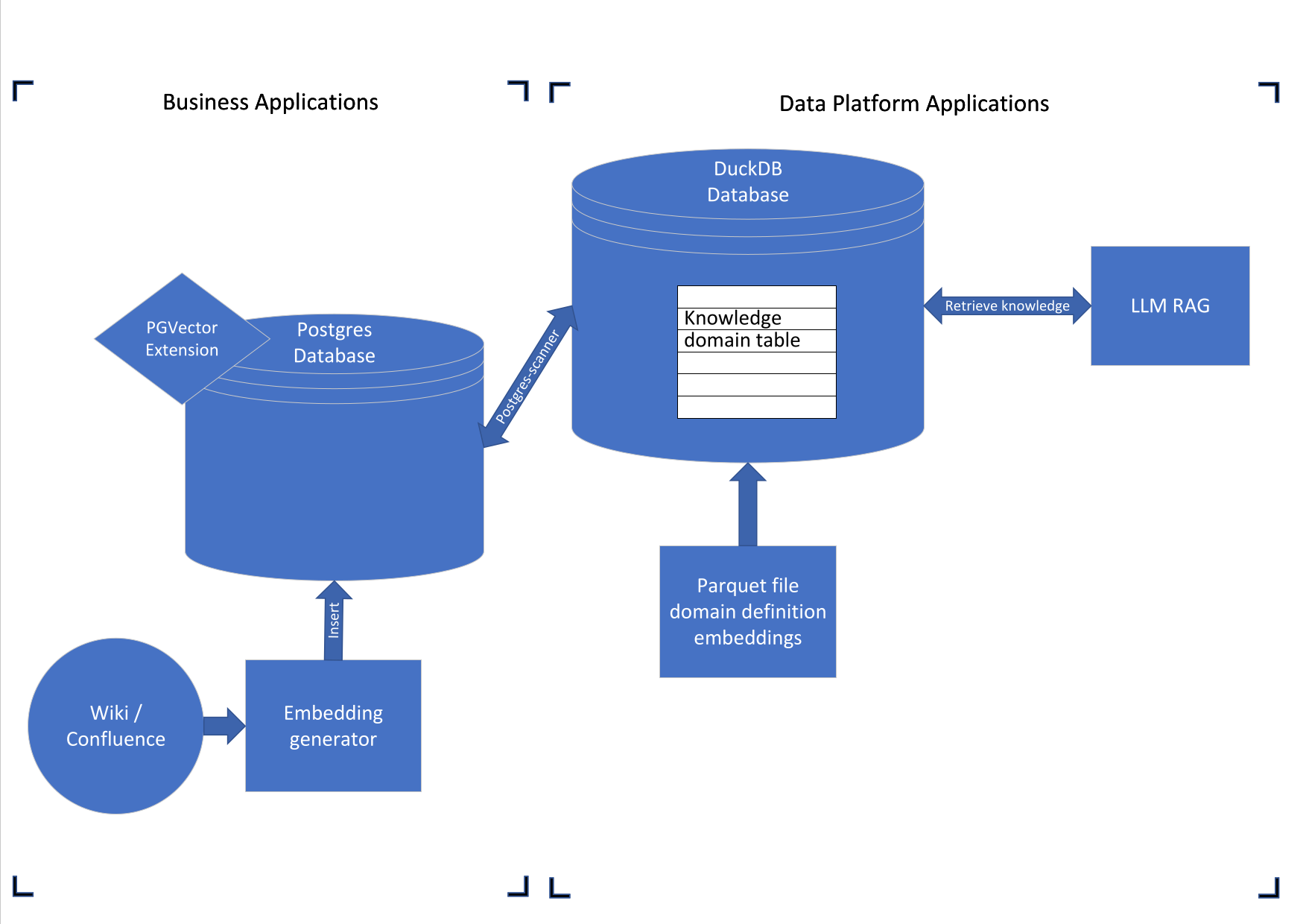
PGVector running within the business application
PGVector is a PostgreSQL extension for efficient vector storage and retrieval (pgvector github). It adds SQL syntax for defining and storing Vectors and for retrieval based on similarity metrics. PGVector is designed to work with high-dimensional vectors, such as those used in machine learning and data analysis (up to 16000 dimensions). It provides functions for vector operations, such as similarity search, nearest neighbour search, and dot product calculation. Approximate indexes can be added to trade increased speed for less precise and non-deterministic results. The transactional nature of Postgres can be very useful when you are embedding a stateful system such as an internal Wiki and want the Vector database to synchronise with live updates made on the Wiki. I envision an embedding model that triggers on wiki page creation/update events and upserts the embeddings into Postgres, which is part of the business application.
PGVector Vector Type
The Vector Type can store 16000 single precision Floats in one Vector value and thus vectors can have up to 16000 dimensions. From the documentation: Each vector takes 4 * dimensions + 8 bytes of storage. Each element is a single precision floating-point number (like the real type in Postgres), and all elements must be finite (no NaN, Infinity or -Infinity). Vectors can have up to 16,000 dimensions
DuckDB
DuckDB is an in process analytical database management system. It aims to be simple following the success of SQLite. It has no external dependencies neither during compilation nor during runtime. This makes DuckDB very portable and open to all kinds of architectural patterns involving very different systems. There is API support for Java, C, C++, Python, Go, Node.js and other languages. DuckDB still is feature rich supporting complex queries, transactional guarantees, persistent storage and deeply integrated with Python and R for data analysis. Our goal for DuckDB is to enable analysis of data using standard SQL queries without the overhead of copying the data to an external system or requiring a specialized query interface. DuckDB is currently in development and close to its 1.x release (mid 2024). The 0.10 release will drop soon and is the major milestone, which 1.x will harden and stabilize (Release Dates - DuckDB). 0.10 comes with the new fixed length Array Type that is very suitable for Vector operations and much faster than the existing List Type for such applications.
Attach DuckDB to Postgres
DuckDB can currently directly run queries on Parquet files, CSV files, SQLite files, Pandas, R and Julia data frames besides Apache Arrow sources. It is very much the spider in the web allowing users to leverage its analytical query engine tuned for the best performance on columnar data. This is impressive for a Database that runs inside our Python process and thus has a tiny footprint in terms of configuration and hosting.
Postgres integration
The goal is to leverage the high-performance analytical engine of DuckDB (OLAP) on top of a Postgres (OLTP) database in a production setting. New data flows into Postgres from business processes. This data can then immediately be used for analytics. To allow for fast and consistent analytical reads of Postgres databases, a “Postgres Scanner” was designed (PostgreSQL Extension - DuckDB , Querying Postgres Tables Directly From DuckDB - DuckDB). This scanner is based on the binary transfer mode of the Postgres client-server protocol. This allows DuckDB to efficiently transform and use the data directly without the need of copying the data across. Multiple connections are opened between DuckDB and Postgres to parallelize the scanning of tables and their processing. These connections are synchronized through a Postgres snapshotting mechanism, so that the state is synchronised and consistent with the state of the database when the query was fired.
Array Type
New in DuckDB 0.10.x is the fixed length Array Type (Array Type - DuckDB). DuckDB already had high performing nested data types of which the Array is the latest addition. An Array is defined by providing a base type and the fixed length integer between brackets, such as Float[10]. There is a natural compatibility between the PGVector Vector Type and a DuckDB Float Array.
Casting PGVector Vectors to the DuckDB Arrays
Postgres allows user to extend its type system such as PGVector did by adding the Vector Type. DuckDB does not know about these user-defined types and represents all of them using the generic VARCHAR type. Within DuckDB queries and table definitions we need to cast the VARCHAR representation of the fixed length Vector Type into an Array of Floats of the same length. This casting will have very little overhead as it is a different interpretation of the same bytes. By performing this cast we enable the Array operations such as cosine similarity within DuckDB based on Postgres data containing vector embeddings.
CAST(embedding as FLOAT[NDIM])
Proof-of-Concept
Here follows the PoC code that demonstrates the DuckDB integration with Postgres for vector embeddings. For testing, VSCode was run with docker-compose devcontainers. Two containers were spun up, one for python development and one running Postgres with the PGVector extension. Docker-compose links the two containers on the same network so that we can make requests with Python to the Postgres database.
PGVector databasing
Create Postgres database
import psycopg
conn = psycopg.connect("postgresql://postgres:hack@localhost:5432", autocommit=True)
conn.execute("DROP DATABASE IF EXISTS vector")
conn.execute("CREATE DATABASE vector")
Creating the Postgres Embeddings table
We first enable the vector extension to allow the use of the User Defined Type Vector in our table definition. This Vector is of a fixed length, which is different from the standard Postgres Array type. This length of the embedding is chosen during table creation as shown below.
EMBEDDING_LENGTH = 1000
with psycopg.connect("postgresql://postgres:hack@localhost:5432/vector") as conn:
conn.execute("CREATE EXTENSION IF NOT EXISTS vector")
with conn.cursor() as cur:
cur.execute("DROP TABLE IF EXISTS embeddings")
cur.execute(
f"CREATE TABLE embeddings (id int, embedding vector({EMBEDDING_LENGTH}))"
)
Insert embeddings into Postgres table
I use pgvector register_vector to create a Postgres connection that is aware of the Vector Type. The insert follows standard SQL. String interpolation is used in the documentation to interpolate Vector values into the INSERT statement. This must have drawbacks when representing Floats. Something that is open for further investigation.
from pgvector.psycopg import register_vector
# Connect to an existing database
with psycopg.connect("postgresql://postgres:hack@localhost:5432/vector") as conn:
register_vector(conn)
embedding = np.arange(EMBEDDING_LENGTH)
conn.execute(
"INSERT INTO embeddings (id, embedding) VALUES (%s, %s)", (1, embedding)
)
# Make the changes to the database persistent
conn.commit()
Query and casting with DuckDB
I use the very interactive ‘duckdb.sql’ usage to explore the functionality and later consolidate this with more proper programming after the 0.10.x release. With the 0.10 release we expect the Array type to be supported across the DuckDB APIs as in my dev build (0.9.3.dev3887) I could not get it to work in the ‘duckdb.connect()’ connection approach
Attach to Postgres
Quite recently DuckDB has improved the ATTACH statement syntax to connect to Postgres. You can pass a property to set read only for the connection. This is useful in our scenario where we are attaching to a live system and do not want to alter the data in the business application.
duckdb.sql(
"ATTACH 'postgresql://<username>:<password>@localhost:5432/vector' AS postgres_db (TYPE postgres, READ_ONLY);"
)
Direct query Postgres
We query the embeddings Postgres table directly with DuckDB and in the select statement we cast the Vector Type bytes to a DuckDB fixed size Array of single precision Floats of the corresponding length.
duckdb.sql("SELECT id, CAST(embedding as FLOAT[EMBEDDING_LENGTH]) FROM postgres_db.public.embeddings")
Integrate vector embeddings from Parquet file
DuckDB allows direct querying of local and remote Parquet files supporting partial reading through both projection pushdown (column select) and filter pushdown (select partitions or zonemaps). For remote storage S3 is well established while Azure support is currently experimental. In practice, many companies first download folders with parquet files to a local filesystem before querying them with DuckDB. Followed by uploading the results as parquet.
# Selecting all data directly from a local domain knowledge parquet file.
duckdb.sql("SELECT * FROM './data/default/domain_a.parquet';")
explicit type casting so is best to CAST the embeddings to VARCHAR before writing to parquet. The reverse cast to an Array of Floats should be done after reading from the parquet file.
Vector similarity query between Postgres and parquet
We want to get the wiki page embeddings that are relevant to our chosen knowledge domain. In practice, we want to find wiki page vectors in Postgres that are similar to domain knowledge vectors stored in Parquet. Thus, we filter wiki context from the live system that lies within a knowledge domain defined by the data platform. Two direct query SELECT statements (one hitting Postgres and the other hitting parquet) are joined based on the cosine similarity of the vectors with a threshold set at 0.7 (to be tuned later). Cosine similarity is one of the most used metrics to measure similarity between two vectors and has the benefit of varying from 0 (no similarity, orthogonal) to 1 (high similarity and aligned) for positive valued vectors. The result is that embedded wiki pages that have a strong relation to knowledge domain will be selected.
duckdb.sql(
f"""--sql
SELECT DISTINCT embeddings.id, embeddings.embedding
FROM
(SELECT id, CAST(embedding as FLOAT[{EMBEDDING_LENGTH}]) AS embedding
FROM postgres_db.public.embeddings)
AS embeddings
JOIN
(SELECT id, CAST(embedding AS FLOAT[{EMBEDDING_LENGTH}]) AS embedding
FROM './data/default/domain_a.parquet')
AS domain_embeddings
ON (array_cosine_similarity(embeddings.embedding, domain_embeddings.embedding) > 0.7);
"""
)
Caching Postgres tables in DuckDB
In general, when a Postgres table is repeatedly scanned then we can cache them in DuckDB to improve performance with the CREATE TABLE <name> AS FROM postgres_db.<table_name>. This will copy over the data. For live updated tables this might make state management harder, but a DROP TABLE followed by a new CREATE TABLE might do the trick.
Storing the domain knowledge embeddings in a DuckDB Table for RAG
The last step for us is to consolidate the wiki page embeddings filtered on the chosen knowledge domain into a DuckDB table for later querying by RAG processes.
# create domain knowledge table
duckdb.sql(
f"""--sql
CREATE TABLE domain_knowledge (id INT, embedding FLOAT[{EMBEDDING_LENGTH}]);"""
)
# insert query result into domain knowledge table
duckdb.sql(
f"""--sql
INSERT INTO domain_knowledge SELECT DISTINCT embeddings.id, embeddings.embedding
FROM
(SELECT id, CAST(embedding as FLOAT[{EMBEDDING_LENGTH}]) AS embedding
FROM postgres_db.public.embeddings)
AS embeddings
JOIN
(SELECT id, CAST(embedding AS FLOAT[{EMBEDDING_LENGTH}]) AS embedding
FROM './data/default/domain_a.parquet')
AS domain_embeddings
ON (array_cosine_similarity(embeddings.embedding, domain_embeddings.embedding) > 0.7);
"""
)
DuckDB as a LangChain context retriever
We have inserted the selected domain knowledge into a DuckDB table for use RAG flows. Currently, LangChain, a popular tool for RAG, supports DuckDB as document loader only. I would like LangChain to start supporting DuckDB as a Vector Store and its retriever interface after the release of DuckDB 0.10.x or 1.x. This would allow LangChain to use a fast in process database within RAG applications for lightweight and fast context retrieval. The portability of DuckDB would make it possible to deploy RAG applications with little overhead and infrastructure requirements.
Conclusion
DuckDB is a spider in the data landscape with high portability and low setup cost. Its integration with Postgres and direct querying of parquet along with all the other integrations and extensions is impressive. For Vector databasing it is lucky that the PGVector Vector Type binary representations matches a DuckDB Array of Floats for low overhead casting in either direct queries or table creation. DuckDB allows multiple sources of embedding vectors to be combined and queried together. As such, we can integrate our Business platform Postgres with parquet files stored in our data platform. Our purpose is to filter the wiki content based on knowledge domain definitions to improve the fidelity of RAG context retrievals. In our proposed architecture the classic gap between OLTP and OLAP databases is bridged. The possibility of decoupling is added by creating DuckDB tables that cache Postgres tables or store query results. After the release of the DuckDB Array type and associated functionalities I await the broader support of DuckDB by LangChain for RAG flows.