Business needs data driven insights to reach stakeholders and customers as fast as possible and with clearly defined freshness requirements. The Lambda architecture (Marz 2015) solves these requirements by combining insights from batch processes and real-time streams into an up-to-date data product. We posit that the Lambda architecture remains a relevant approach to deliver insights for data science teams with limited engineering capacity. We expound on the creative ways to fuse batch and streaming insights and present our Azure Lambda implementation, as an illustration.
Lambda architecture overview
The Lambda architecture was well expounded by Nathan Marz (book, 2015). The Lambda architecture consists of a batch layer, a speed layer and a serving layer and is aimed at delivering up-to-date update-to-date insights. The batch layer uses the master dataset to overwrite the batch view each time it runs. These precomputed batch insights are our source of truth. In between batch pipeline runs, streaming updates from the speed layer are used to keep our insights fresh. This is best effort, as any mistakes accumulated from streaming updates are discarded by the next batch pipeline run. The serving layer combines the batch and real-time view into an up-to-date data product in response to queries.
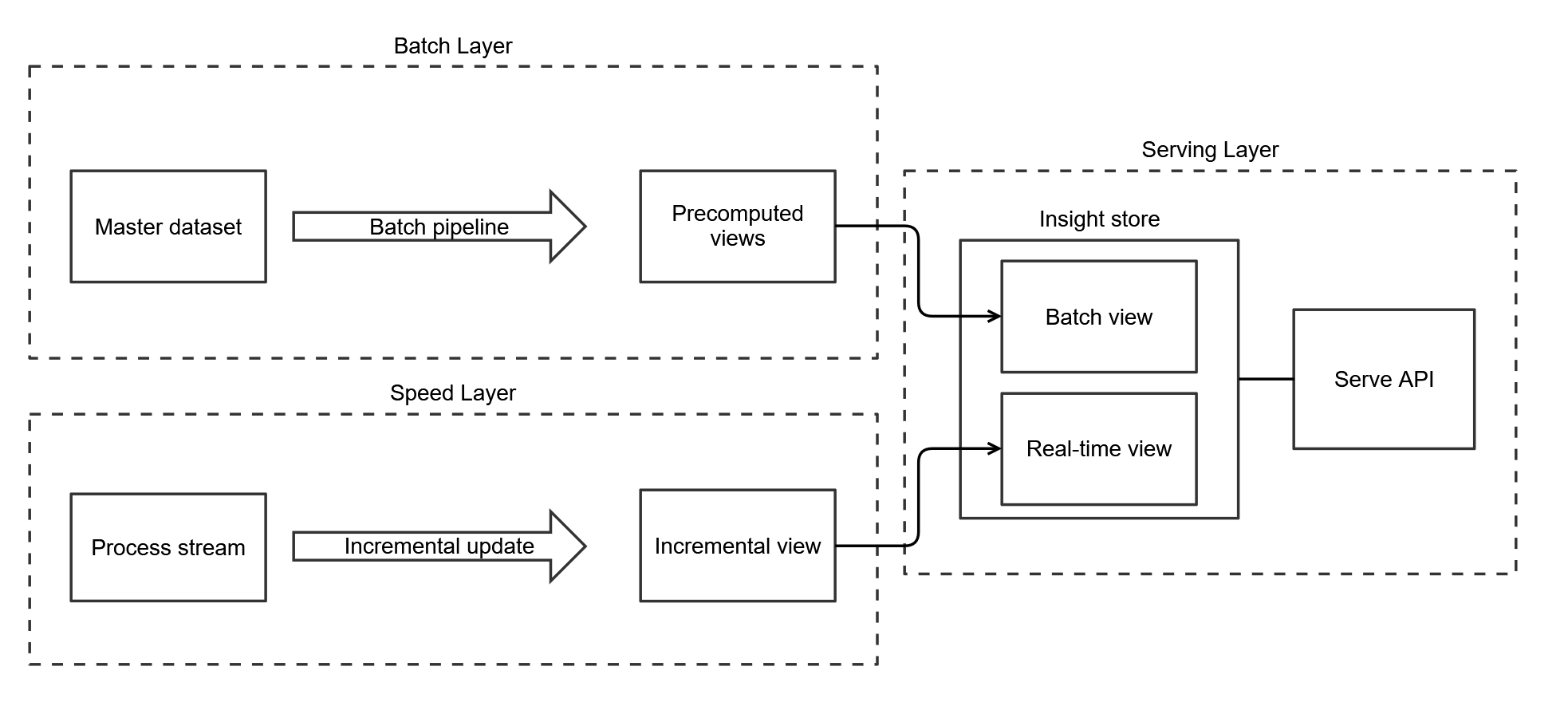
Lambda for data science
The Lambda architecture is suitable for modern data science teams wanting to deliver real-time insights to business and customers. Often there is already a batch layer present and the need for fresher insights is an add-on requirement. The existence of a batch layer might also have good reasons, such as aggregations or training of machine learning models on historic data. The makeup of a data science team with around 30% data engineering capacity fits well with the pragmatic self-healing capability of the Lambda architecture.
Why not kappa?
Kappa architecture involves fully fledged event sourcing. The source of truth is not the batch pipeline (which is absent), but the accumulated state across past streaming events. There are blogs (such as this) describing failed projects based on event sourcing. One of the harder things to manage is error recovery. Imagine you have made a mistake in your streaming logic and have a hotfix ready. In Lambda we would deploy the fix to the speed layer and a triggered or scheduled run of the batch layer would selfheal our insight store. In Kappa we would have to replay a large chunk of historic streaming events possibly across multiple applications and eventhubs (parsers, insight producers) and validate our new state against our expectations. This is more engineering intensive and not the best fit for a data science team with limited engineering capacity.
The magical fusion between batch and speed layers
The synergy between the batch and speed layer is where the magic happens. It is often a creative process to apply the Lambda architecture. The goal is to keep logic in the serving layer to a minimum with an appropriate structure of the batch and real-time views. There are three general ways to fuse the batch and speed layer and, these are not mutually exclusive, namely:
- Update precomputed batch view aggregates with streaming insights
- Use a batch generated lookup table or ML model in the speed layer
- Business entity state updates (accumulated, full, or partial)
- For example, updating the predicted account balance of a customer
In this section we will refrain from implementation details and whenever we mention a Kafka topic, we mean any event log such as Azure eventhub or Kafka itself.
1 Update precomputed aggregates
This fusion was featured heavily by Marz (2015). The batch layer precomputes aggregates as our recurring source of truth. Streaming updates are combined with historic aggregates to respond to queries with up-to-date aggregates. In the classic example of website visitor counts, aggregates are partitioned per hour in the batch view. Real-time site visits are stored with timestamps in the real-time view (preferably a key-value store). A REST call triggers a function receiving both the historic aggregates per hour and all available real-time visits. The updated aggregates are computed and returned as our response. Note that, the returned aggregates can have different aggregation periods (i.e., days, months) than those stored in the batch view.
1.1 Query optimization
The site visit aggregates can be recomputed with streaming website visits that are more than an hour old and again stored in the batch view. The processed speed layer site visits can then be discarded, which will shorten query response times.
1.2 Variations on insight aggregation
The Lambda architecture is flexible in its application. There are various scenarios that might fit the aggregation fusion, but with a twist.
- We return the union of batch and real-time insights.
- We want to hash identifiers in the batch view with a changing salt from the real-time view to anonymize our responses
- Bayesian correction of stored model predictions by real-time evidence
2 Batch generated lookup table or ML model
Often, we need an intermediate product from the batch layer to generate insights in the speed layer. For instance, a lookup table and trained ML model created in the batch layer are used to enrich and classify insights in the speed layer. The batch pipeline creates new versions of these artifacts every time it runs. Often, we want to use only the latest versions but for ML models MLOps can be applied to decide to use the latest model only if it is better than a previous version.
2.1 Lookup table
How do we share a lookup table between the batch and speed layer? A basic approach lets the batch layer write the lookup table to storage. The batch pipeline could restart the stream processing in the speed layer to force reload of the latest version of the stored lookup table, although this not so elegant. More elegant would be to reload the lookup table from disk with a fixed interval without interrupting our stream processing (implementation details follow later). Another approach is to write the lookup table and its versions to a Kafka topic and stream-stream join it in the speed layer. This last approach would require added complexity to only use the latest version of the lookup table, such as log compaction.

2.2 Trained ML model
For trained ML Models created by the batch layer, we consider versioned models stored in the model registry and deployed behind its own REST API (depicted with AzureML inference deployments). We stream each unique URL of a model version into a Kafka topic with metadata attached (depicted with Azure eventhub). The metadata contains a prediction date range for which the model version is applicable. We join the speed layer messages with the model URLs eventhub based on the prediction date and call the model API to attain the prediction, which is incorporated into our streaming insight.

3 State updates
The third way to fuse batch and streaming insights is to focus on state management of business entities, some examples are:
- Real-time generated predictions per customer overrule batch view predictions
- Flag predicted transactions as processed transactions based on real-time transaction stream
- Update the credit rating of a customer based on the real-time output of various models
This stateful fusion is different from the fusion described in section 1, because aggregates provide insights across business entities and time. Here, we want to manage insight state on the level of individual customers with detailed information flowing through the batch and speed layers. State management in real time analytical systems is hard, due to non-guaranteed event processing order, library limitations, datastore performance and logical complexity.
3.1 Business entities and object constancy
Insights make statements about business entities, such as the predicted value of a customer, the crowdedness of a specific train or the sentiment of a forum user. Naturally a separate state is maintained for each business entity in the insight store. To allow state separation we need to consistently identify business entities across our system, which constitutes object constancy. There are a few ways we can identify business entities.
- A unique data product key (unique combination of field values, such as customer_id, bank_account_number)
- A match scoring function, matching insights with stored insights
- Similarity metrics
- Unsupervised clustering
- MinHash or other bucketing approaches
- Custom scoring functions
- A combination of the previous two
We illustrate the third option (combined approach) with bank transactions. Each transaction has a unique sending and receiving bank account number, which together constitute a unique data product key. The two bank account numbers combined identify a financial relationship. For example, the financial relationship between student and university, we could see transactions with different subjects. Such as, regular tuition payments by the student, and occasional payments for course material. In this case, we want to predict the costs of course material for next year. To disentangle these two groups of transactions we score their similarity on transaction message and amount. We end up with two sets of transactions under one financial relationship. These two sets are both business entities and we want to select one for our insight generation and state management.
3.2 Full state update
With full state updates the speed layer insights overrule the batch layer insights. Effectively insights in the real-time view replace insights in the batch view. The insights in the batch view do not need to be overwritten, but the serving logic gives the real-time view precedence when responding to queries.
3.3 Partial state updates
The speed layer might not be able to generate a complete insight and be limited to partial updates. For example, state transitions are often communicated by partial state updates, such as transitioning a prediction to a historic fact. Here, we update the definite value and the state of the record from predicted to actual. With partial updates we often use a single view in the serving layer (Fig. 4). The batch layer overwrites this single view (taking care of record deletes) and the speed layer patches records/documents in the same view. This keeps the architecture self-healing as each batch pipeline run will completely overwrite the insight store.
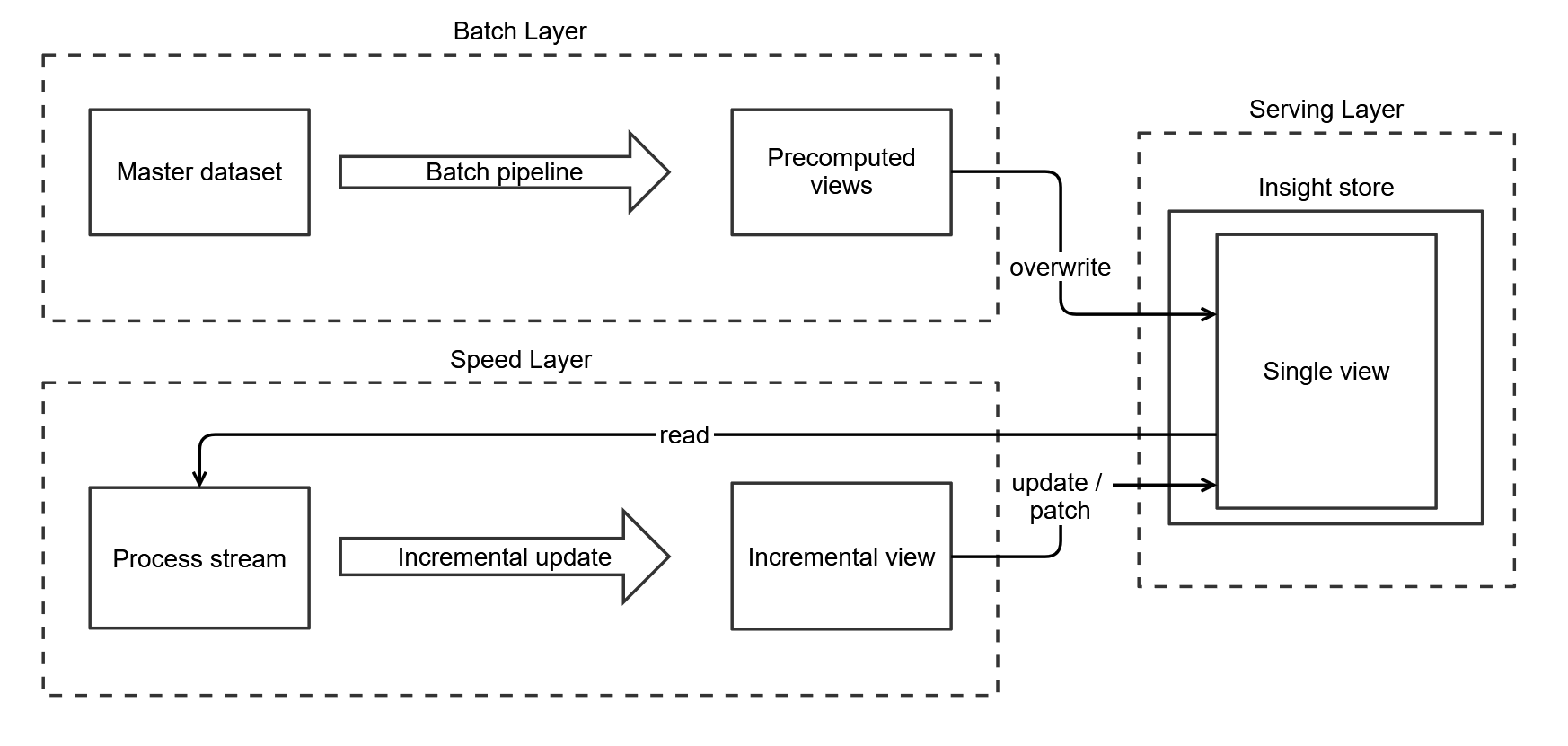
3.4 Accumulated state updates
Accumulating state updates are not idempotent, because the outcome of the state update depends on the current state. This is different from full or partial state overrules and becomes harder to maintain in high throughput (>100 updates per second) streaming systems. Apart from other general streaming limitations, micro batch streaming frameworks suffer from concurrency problems when updates across concurrent micro batches target the same state. Therefore, accumulated state updates might require continuous stream processing. Some examples of state accumulation are:
- Flagging as “processed” a list of predicted bank transactions with real-time transactions
- Accumulating a prediction value based on input of different models at different times
As with partial updates we sink both the batch and speed layer into a single insight store view. The batch layer overwrites the insight state to keep the self-healing properties of the Lambda architecture, and the speed layer mutates it. Accumulative updates read the current insight state, mutate it, and overwrite it. To this end, we need a fast key-value store to support fast operations on the level of individual business entities, such as HBase.
Azure data science Lambda Architecture
Each implementation of the Lambda architecture is different, due to available technology and business requirements. We deliver AI data products as part of an Advanced Analytics department. Our language is Python, and we use it throughout. Our AI team is committed to Spark and Databricks for batch processing, which was naturally extended to stream processing with PySpark structured streaming and other Azure offerings (eventhubs, functions and the not shown stream analytics). Azure eventhubs are central to stream processing and valuable for batch results as well.

Batch layer
The Batch pipeline runs twice daily, during the night and at noon. An important source for our predictions is streamed throughout the day and the additional noon run improves our predictions strongly. The batch pipeline results are loaded directly into a CosmosDB batch view container by batch view loader application. Building up the state in CosmosDB from the batch eventhub would be ideal, but for now performance seems to prefer using the spark connector. The two daily runs overwrite each other’s results in CosmosDB, and both runs write their results to the batch eventhub for downstream consumption. Each message in the eventhub is one document in CosmosDB and is one prediction generated by our models in a standardized format.
Speed Layer
The speed layer consumes a subset of upstream sources and writes them to eventhubs within our domain after parsing them. Such single source parsing logic is executed on an azure function with an eventhub trigger and output binding. The domain eventhubs are consumed by our main PySpark structured streaming Databricks application, which generates the incremental updates and writes them to the updates eventhub for downstream consumption and loading into the CosmosDB real-time view. The Azure function eventhub trigger to load CosmosDB is feasible due to lower peak traffic compared to the batch layer. Currently, we fully overrule the state in the batch view with empty predictions in the real-time view per unique data product key.
Lookup table refresh
The batch layer generates a lookup table we need in the speed layer to generate insights. A Spark structured streaming static-stream join allows us to use a stored DataFrame lookup table in Spark structured streaming. There is no direct support for reloading this “static” DataFrame, besides restarting the stream processing.
But if we want to periodically reload our lookup table to get the latest, we can use a combination of “hacky” mechanisms. Setting up a “rate” readStream in combination with a function called after processing each micro-batch to reload the static DataFrame in the outer scope. It is a bit of a hack, but it seems to work for lookup tables stored on disk (see 1 and 2).
Serving Layer
Our AI data product is exposed in two ways, a REST API and two eventhubs (batch and updates). Document formats between the batch and real-time views are identical and can be served immediately as JSON, which reduces complexity of serving logic in our web app service. In response to a request both containers are queried for all relevant predictions. Only one prediction is returned business object and the real-time view takes precedence. In all, our approach kept things simple in its current incarnation. Let us hope we can keep it simple!
Implementation Wish list
We have some wishes to expand on our current Lambda architecture implementation. These are added to Figure 6, namely:
- We would like to sink the batch and updates eventhub directly into CosmosDB
- The eventhubs would also constitute a secondary serving capability to our stakeholders
- Throttling the Spark eventhub connection to reduce maximum required eventhub throughput units
- The capability to recompute predictions in the speed layer based on pretrained ML models
- The capability to elegantly refresh a static lookup table used stream processing

Wish list point 3 can be achieved following section 2.2 by adding a model registry (AzureML) to register models trained in the batch pipeline. If MLOps decide the latest model is better than previous models we deploy the model for inference with AzureML and send the model API URL to the eventhub along with the prediction date range. We join the speed layer with the model URLs eventhub based on the prediction date and filter models valid for that date. We can handle the calls to the model API in parallel for the streaming messages with a PySpark structured streaming Python UDF (example github). If a new model URL is pushed to the eventhub it will generate new insights for its date range, which will overwrite the insight store state in CosmosDB. This approach of resolving the “latest” state in a document store is called log projection and preferred by Microsoft over log compaction (log projection). The other two wish list points are dependent on Microsoft and Databricks for providing us with the right tools or choosing different technologies. For instance, Apache Druid can be a sink for eventhubs and might be an alternative to CosmosDB. Thank you for your Attention!