Veilige MLOps met Databricks MLFlow
Waarom één Databricks-workspace?
Een veilige Databricks-workspace wordt uitgerold in virtuele netwerken, die aparte subnets vereisen voor de control plane en de compute plane. Het IP-bereik van het compute plane-subnet beperkt het maximale aantal parallelle compute nodes dat tegelijkertijd gebruikt kan worden. Vanwege bedrijfsbrede beperkingen op de omvang van IP-bereiken kozen we ervoor om één groot subnet voor één Databricks-workspace te gebruiken in plaats van meerdere kleinere subnets gekoppeld aan meerdere Databricks-workspaces. We willen dus meerdere logische omgevingen (acceptance, preproduction en production) binnen één Databricks-workspace beheren.
Schalen met Databricks pools
Databricks pools maken het mogelijk om inactieve instances (virtuele machines) te hergebruiken bij het aanmaken van clusters. Pools bieden bescheiden snelheidsvoordelen bij het opstarten en auto-scalen. Elke instance in de pool vereist één IP uit het compute plane-subnet. Als het maximum is bereikt, mislukt het volgende verzoek om een instance aan te maken, zonder enige elegante foutafhandeling of backoff-mechanisme. Door deze beperking van de Databricks pools is het belangrijk om een groot subnet te hebben voor je activiteiten, want je kunt op elk moment tegen het maximum aanlopen en dan crashen je applicaties.
Identity-gebaseerde beveiliging
Onze beveiligingsaanpak is gebaseerd op identities, voornamelijk application registrations in Azure en Databricks-gebruikers die worden ondersteund door ADD-gebruikers. We draaien bijvoorbeeld onze acceptatietests in dezelfde Databricks-workspace op productiedata met aparte identities die read-only permissies hebben om productiedata te kopiëren naar tijdelijke storage accounts voor acceptatietests. Identities zijn erg handig op Azure, omdat Databricks credential passthrough ondersteunt waarmee alle Azure AD-rollen en -groepen die we op de identities instellen, worden benut. We vertrouwen ook op Databricks-permissies en -groepen, aangezien we met meerdere identities in één Databricks-workspace werken.
Databricks-groepen
Elke logische omgeving in onze enkele Databricks-workspace heeft een Databricks-groep voor zijn application principals met de naam f”apps_{env_name}” (oftewel apps_acc, apps_prod) en een groep die alle actieve application principals bevat, “apps_all”. De groepen en hun permissies worden beheerd met terraform.
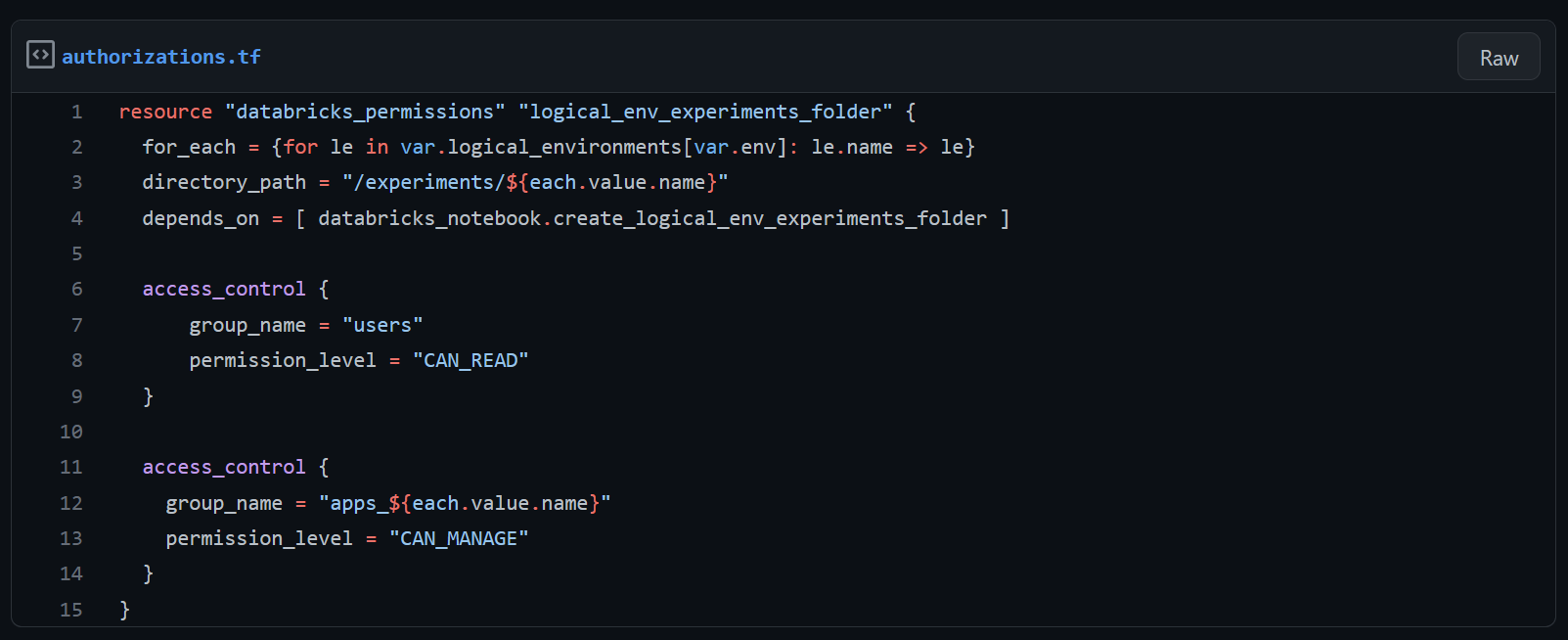
Omgevings-MLFlow-client
MLFlow experiment tracking
De opslag van MLFlow-experimenten is aangepast om meerdere logische omgevingen te ondersteunen door de opslaglocatie per omgeving te beheren. Onze oplossing wijst directories toe zoals “/experiments/acc” en “experiments/prod” om experimentdata op te slaan. Het permissiebeheer van Databricks wordt gebruikt om directoryrechten toe te kennen aan de respectievelijke Databricks-groepen (in dit voorbeeld “apps_acc” en “apps_prod”). Dit maakt veilige logging van experimenten en modellen voor elk van de logische omgevingen mogelijk, zonder dat de gebruiker erover na hoeft te denken.
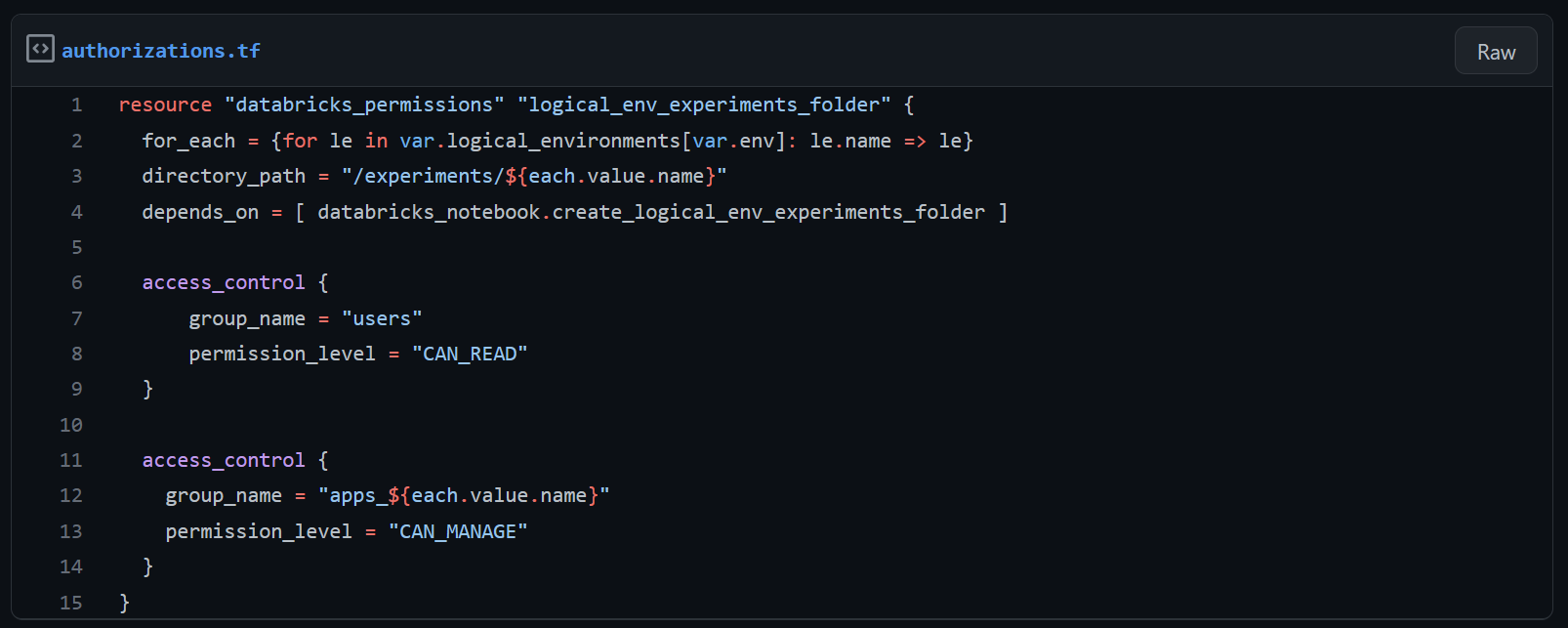
MLFlow model registry
De MLFlow model registry is een centrale plek om modellen en modelversies te registreren voor gebruik in ML-systemen. Modellen die tijdens data science-experimenten in verschillende omgevingen worden gelogd en geregistreerd, komen terecht in dezelfde model registry. De MLFlow model registry is lastiger aan te passen voor gebruik met meerdere logische omgevingen. Het deployment target-concept in MLFlow gaat er namelijk van uit dat elke versie van een specifiek model een andere “stage” kan hebben. De model stage is een eigenschap van een modelversie die in de MLFlow model registry is geregistreerd. Deze kan worden ingesteld op “None”, “Staging”, “Production” en “Archived”. Hoewel de model stage nuttig is, is hij behoorlijk beperkend omdat we er geen eigen waarden voor kunnen definiëren, en daardoor ondersteunt hij onze behoefte om diverse logische omgevingen te definiëren niet volledig. We gebruiken hem wel om permissies op onze modelversies met Databricks te beheren, wat we later beschrijven.
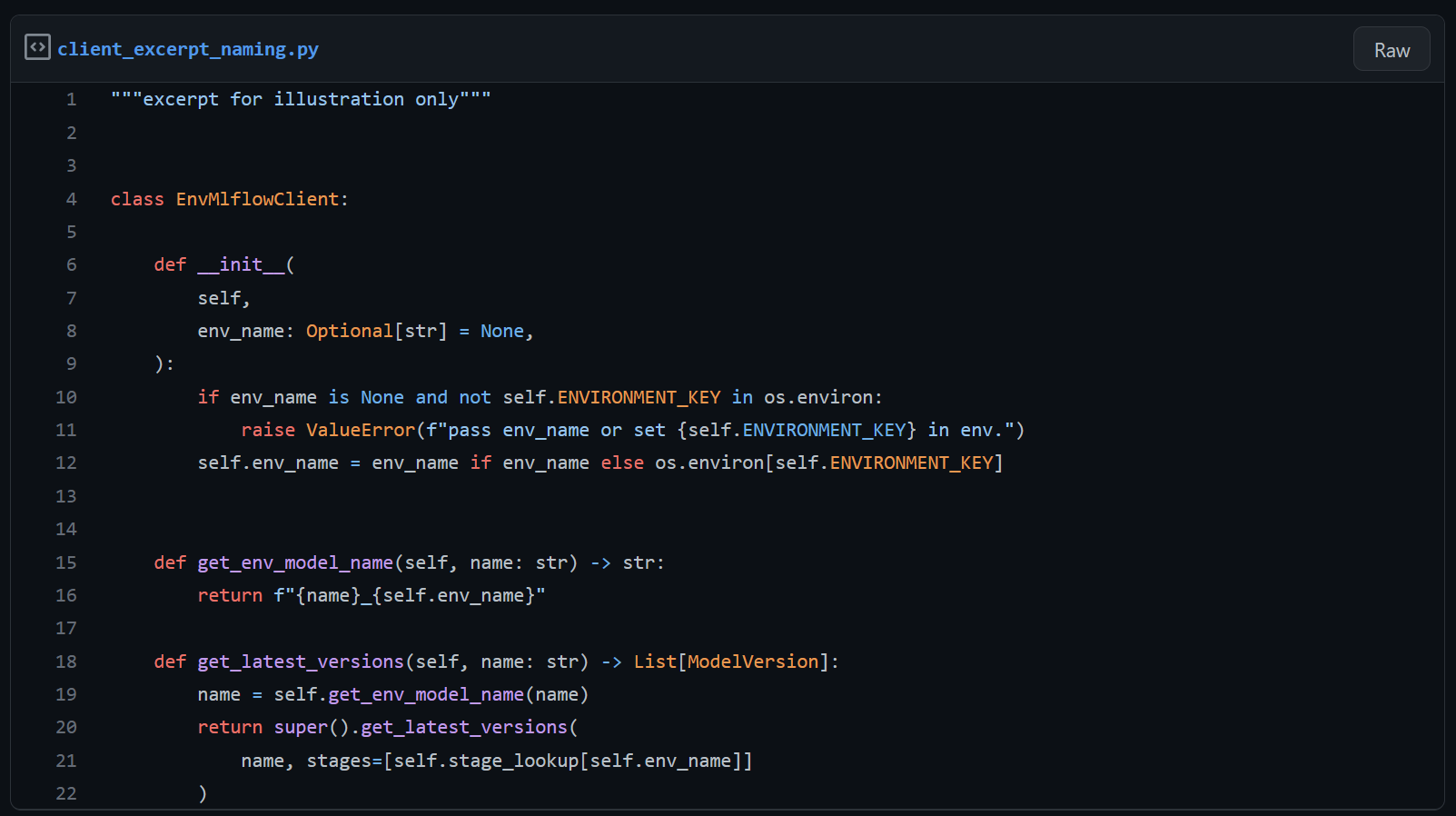
Model naming
We besloten dat model naming onze eerste laag wordt om te differentiëren tussen een willekeurig aantal logische omgevingen. Elke geregistreerde modelnaam wordt voorzien van een postfix met een omgevingsidentifier f”{model_name}_{env_name}”. Onze MLFlow-client beheert deze naamgeving transparant tijdens modelregistratie en -ophaling op basis van de omgevingsnaam die hij krijgt uit een system environment variable of de omgevingsnaam die aan zijn constructor wordt doorgegeven. Net als bij het experimentbeheer is de interface grotendeels ongewijzigd ten opzichte van vanilla MLFlow, dankzij onze abstractie binnen de omgevings-MLFlow-client.
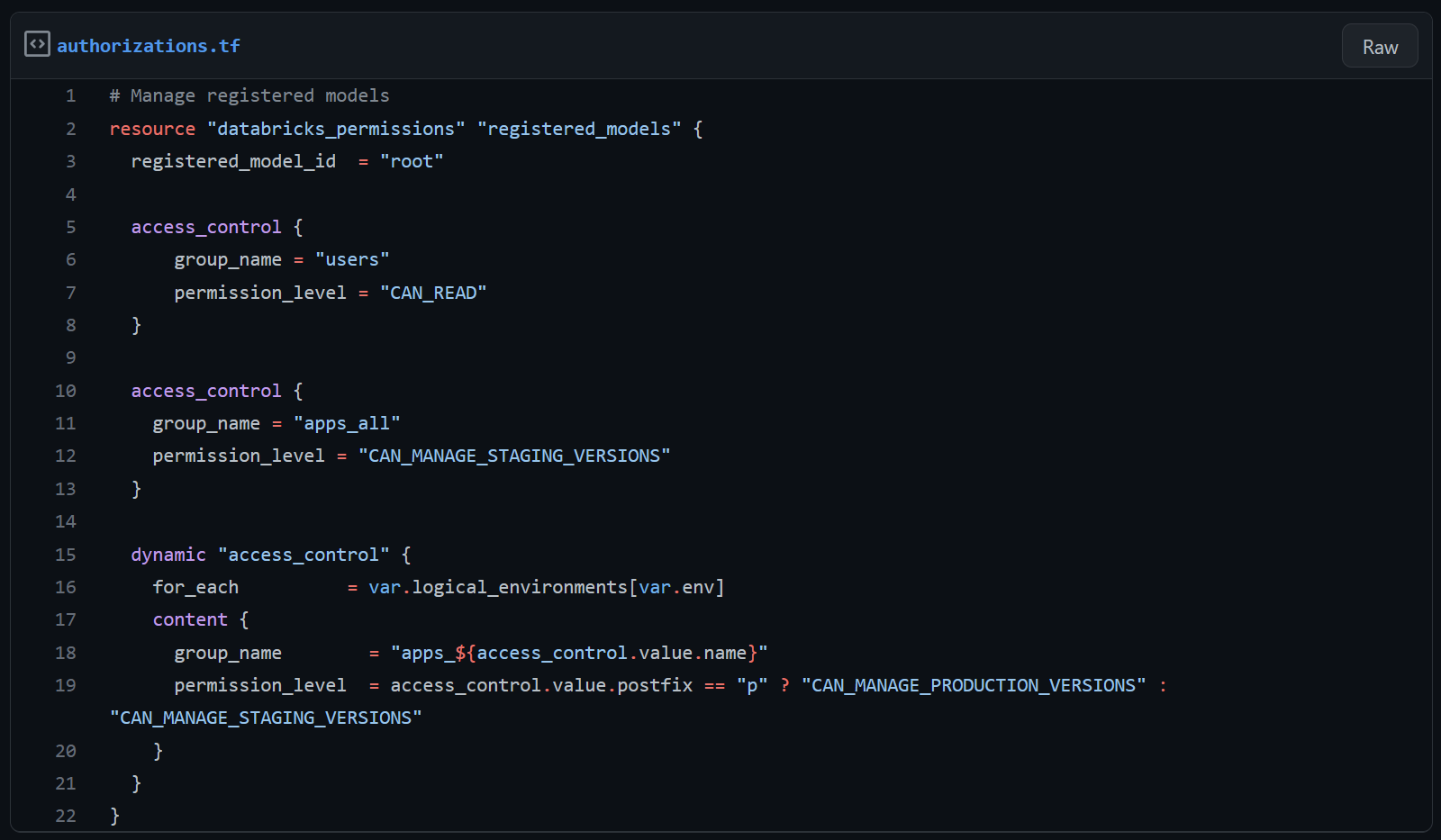
Modelpermissies
Ons doel is om productiemodellen te scheiden van elke andere omgeving en te voorkomen dat een niet-productie-principal productiemodelversies registreert of ophaalt. Zoals genoemd kan de model Stage worden ingesteld op “None”, “Staging”, “Production” en “Archived”. Het permissiebeheer van Databricks haakt in op de waarden van de model Stage. We kunnen bepalen wie de waarden “Staging” en “Production” van de model Stage mag instellen en wie modellen met deze model Stage-waarden mag beheren, met behulp van de permissies “CAN_MANAGE_STAGING_VERSIONS” en “CAN_MANAGE_PRODUCTION_VERSIONS”. De “Production” Stage-permissie staat principals ook toe om “Staging” Stage-modelversies te benaderen en deze om te zetten naar productiemodelversies.
Om Productiemodellen te scheiden van modellen uit andere omgevingen kennen we de model Stage automatisch toe bij het registreren van een modelversie. Alle niet-productieomgevingen kennen de model stage-waarde “Staging” toe. Modelversies die vanuit de productieomgeving worden geregistreerd, krijgen de stage-waarde “Production”. We benutten de Databricks-permissies die zijn toegekend aan onze Databricks-groepen, hieronder getoond, om onze Productiemodellen veilig en gescheiden van andere logische omgevingen te beheren.
Alles samenbrengen
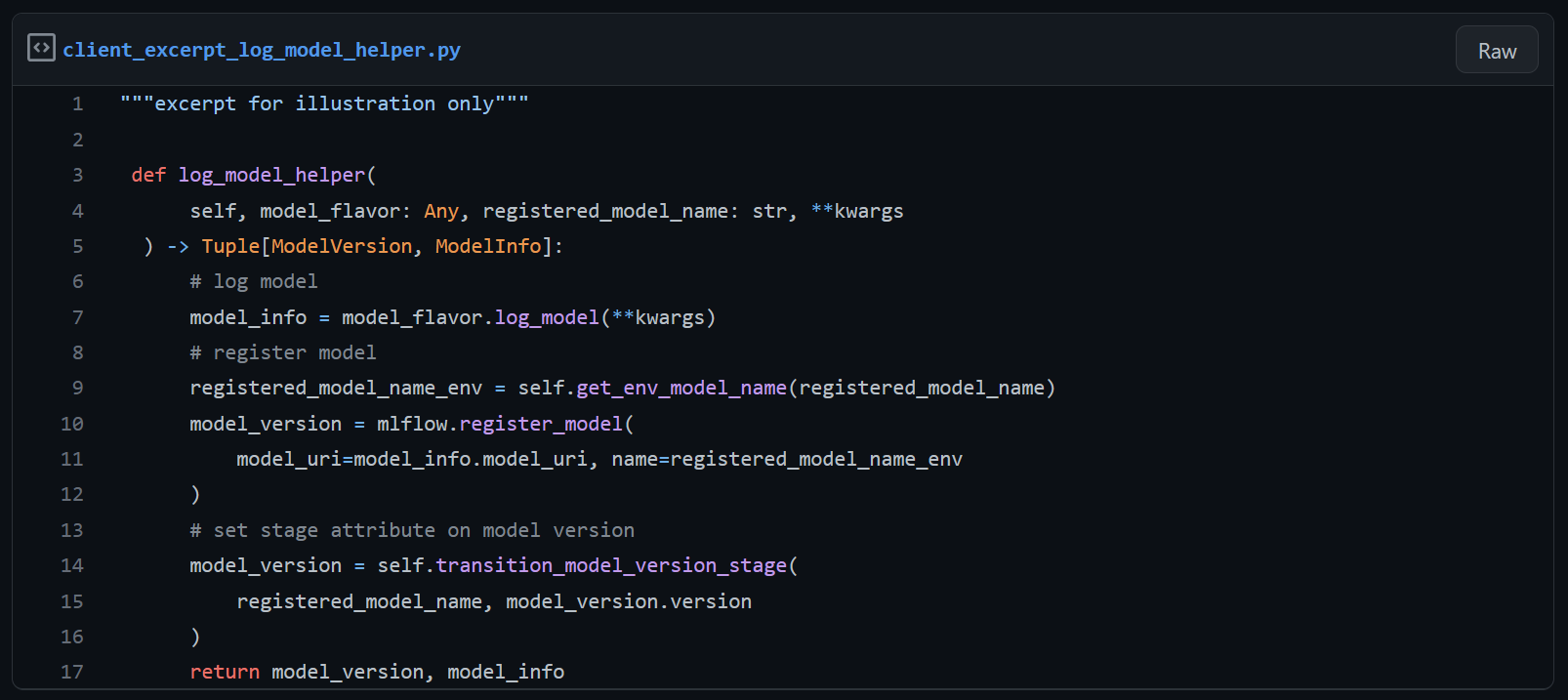
Naast abstracties bovenop de vanilla MLFlow-client hebben we een paar methods toegevoegd die diverse acties voor je gemak omhullen. Een van de extra methods is de “log_model_helper”, die de verschillende stappen afhandelt om een modelversie te loggen en registreren en de juiste model stage in te stellen.
Een modelversie registreren gebeurt doorgaans in twee stappen: eerst loggen we een model tijdens een experiment run en daarna registreren we het gelogde model als een modelversie van een geregistreerd model. Een model loggen tijdens een experiment run geeft een ModelInfo-object terug, dat een model_uri bevat die verwijst naar de lokale artifactlocatie. We gebruiken de model_uri om een modelversie te registreren onder een geregistreerde modelnaam en deze te uploaden naar de MLFlow registry. Het registreren van een modelversie geeft een ModelVersion-object terug dat ons de automatisch opgehoogde modelversie en de current_stage van het model vertelt, die direct na aanmaak altijd “None” zal zijn.
Onze derde stap tijdens de registratie van een modelversie is om de modelversie-stage over te zetten van “None” naar “Staging” of “Production”, afhankelijk van de logische omgeving. Iedereen kan modelversies aanmaken, maar de Stage-overgangen zijn beperkt met de Databricks-permissies. Deze drie stappen zijn omhuld in de “log_model_helper”-method. Met deze helpermethod kunnen we ervan uitgaan dat alle geregistreerde modelversies een omgevingsbewuste naam en de juiste stage-waarde hebben.
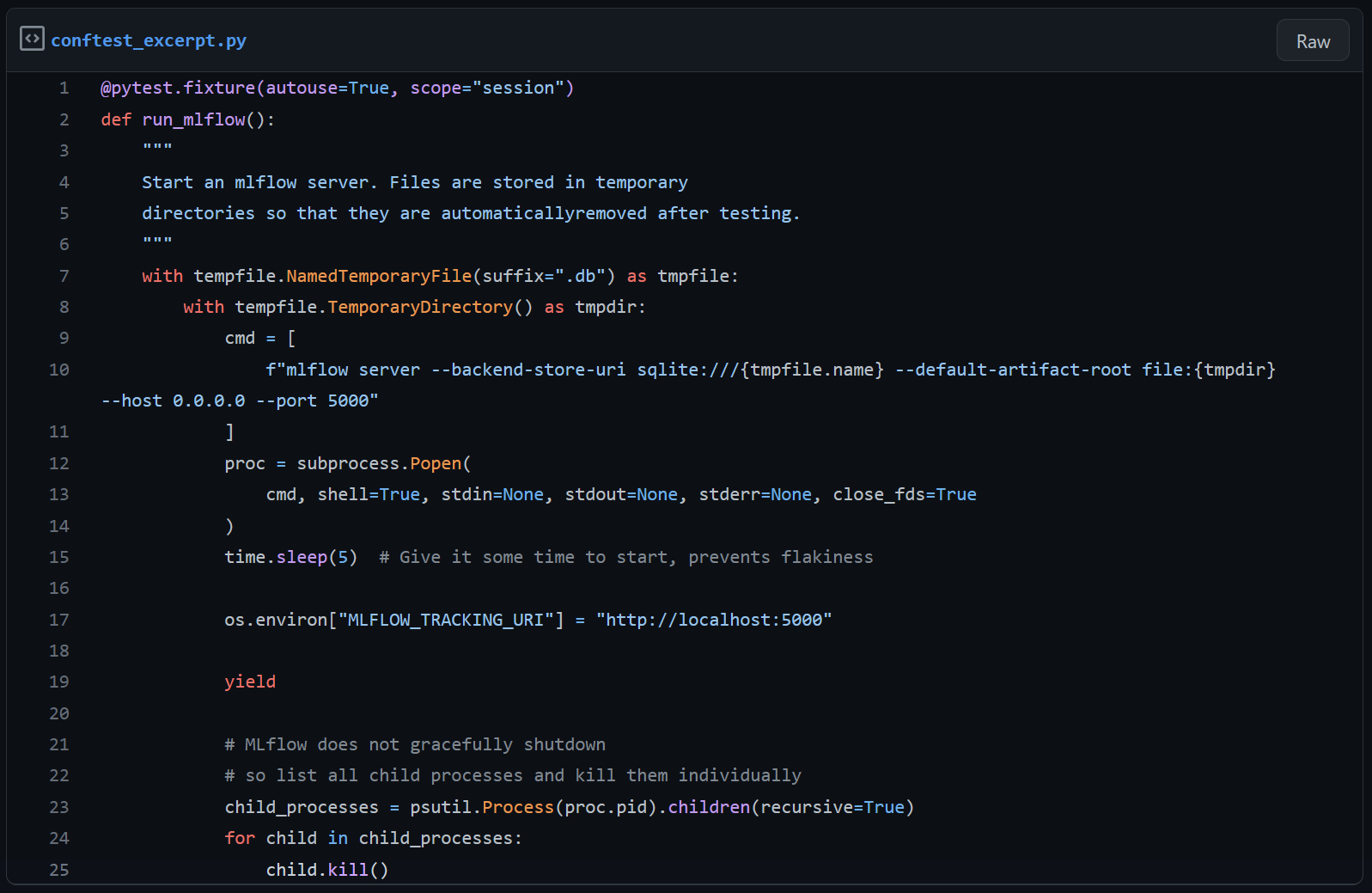
Onze MLFlow-client testen
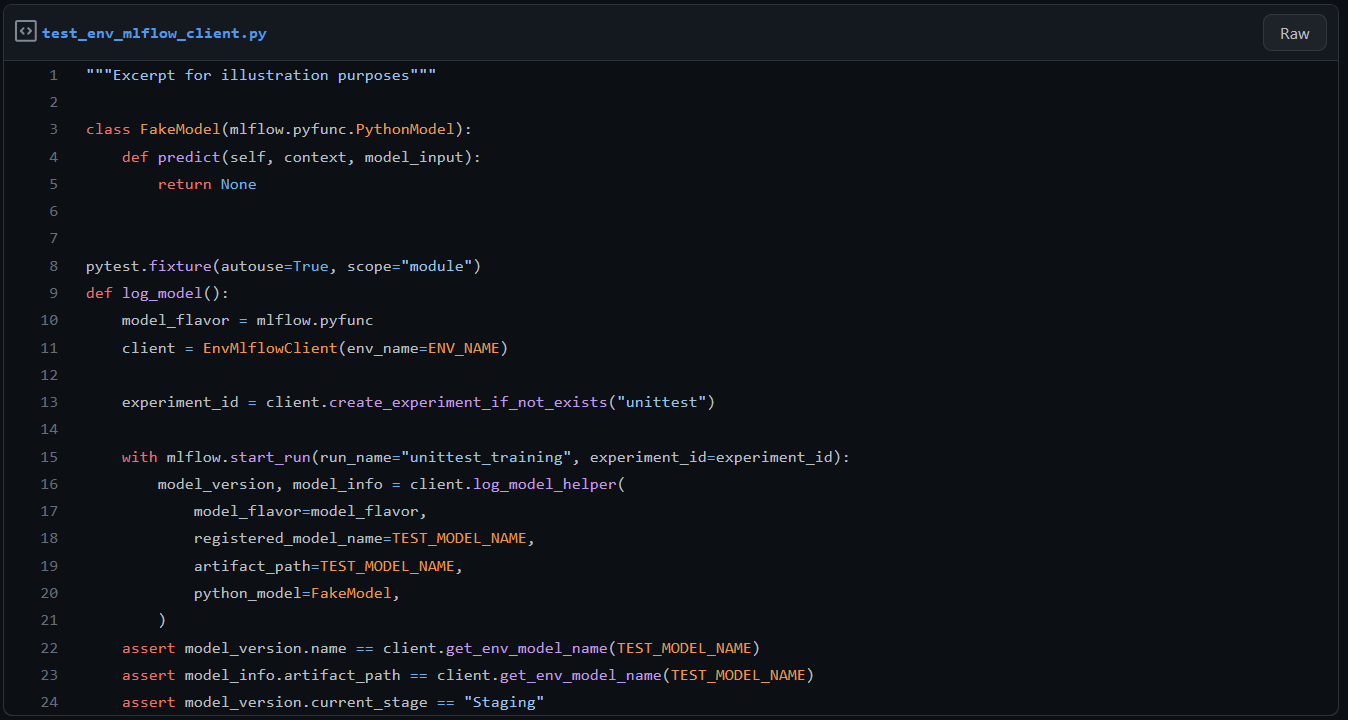
Om onze eigen client te onderhouden, moeten we hem in detail testen om te controleren of hij voldoet aan ons permissieontwerp. Eventuele wijzigingen in de upstream MLFlow-client worden tegelijkertijd getest, bijvoorbeeld een herstructurering van de MLFlow-modules. We starten een lokale MLFlow-server binnen een PyTest fixture die scoped is op de hele testsessie. De Python tempfile-module wordt gebruikt om een tijdelijke artifactlocatie en een tijdelijk sqlite-databasebestand te genereren. Het doel van onze testsessie is om een model te loggen en registreren en er diverse mutaties en ophalingen op uit te voeren. De eerste stap is om een modelversie te loggen en registreren in de lege model registry. We doen dit binnen een PyTest fixture, omdat alle andere tests ervan afhankelijk zijn, hoewel het technisch gezien zelf een test is, aangezien het asserts bevat.
Conclusie
Onze uitgebreide omgevings-MLFlow-client stelt ons in staat om modellen vanuit meerdere logische omgevingen in dezelfde model registry te registreren. Hij benut de minimale permissieopties in Databricks om ontwikkelomgevingen veilig te scheiden van productie. Bovendien is de MLFlow-API grotendeels ongewijzigd en hetzelfde over alle omgevingen heen.