Vector databasing met DuckDB bovenop PGVector
Er wordt een architectuur gepresenteerd die DuckDB met Postgres integreert voor vector databasing, met behulp van het nieuw toegevoegde DuckDB Array type en bijbehorende functies. Het doel van de architectuur is om bedrijfsapplicaties te scheiden van analytische applicaties, maar zonder verlies van consistentie of grote latenties. Ik wil laten zien hoe je verschillende tools integreert om de kloof te overbruggen tussen bedrijfs- en data-applicaties met hun respectievelijke OLTP- en OLAP-databases.
Vector embeddings van digitale assets
Digitale assets zoals afbeeldingen, tekst, audio en video kunnen als reeksen getallen aan AI-modellen worden gevoerd. Hun RAW-representatie is mogelijk niet de meest effectieve om in AI-modellen te stoppen. De modellen kunnen gevoelig zijn voor de ruis van de RAW-representatie en de relaties en objecten binnen de digitale asset missen. Embedding AI-modellen zijn geoptimaliseerd om representaties van hun input te creëren op basis van een referentie-vectorruimte. Deze referentie-vectorruimte is getraind op grote datasets en maakt reductie van dimensionaliteit en daarmee opslagruimte mogelijk. De resulterende vector embedding codeert de objecten en hun context van relaties met andere objecten en hun relaties tot andere objecten binnen het domein. Embeddings die door een specifiek embedding-model worden gegenereerd, hebben een vast aantal dimensies, gerepresenteerd als een array van floating-point getallen.
Vector Databases
Vector Databases zijn een beetje een Hype, maar zijn belangrijk geworden in de meeste LLM-applicaties die sterk leunen op vector embeddings voor het ophalen van context als reactie op prompts. Ze maken opslag van hoogdimensionale vectoren mogelijk en bieden methoden om de top-N meest vergelijkbare vectoren op te halen op basis van een input-vector. Vector indexing wordt toegepast om dergelijke ophaalacties te versnellen.
Retrieval Augmented Generation (RAG)
Een essentiële stap in de voorbewerking vóór het bevragen van de LLM is het ophalen van context die sterk lijkt op de prompt die door de gebruiker is ingediend. Het ophalen van contextuele informatie op basis van similariteit is de kracht van de Vector database of ieder vergelijkbaar systeem. Hier gebruik ik context die met lage latentie beschikbaar is in bedrijfsapplicaties, om ervoor te zorgen dat modellen verwijzen naar de meest recente beschikbare informatie die door de bijdragers wordt gemodereerd. Hieronder is een deel van de RAG-flow weergegeven. Het relevante deel voor deze blog is het ophalen van de vergelijkbare content uit de vector database door de embedded representatie van de prompt van de gebruiker aan te leveren. De vector database bevat actuele domeinkennis die niet beschikbaar was tijdens de oorspronkelijke training van de LLM, noch tijdens latere finetuning van de LLM. In deze blog selecteer ik domeinspecifieke kennis om naar de vector database te schrijven uit een grotere set beschikbare informatie, om de ruis in het ophaalproces op basis van similariteit met de prompt te verminderen.
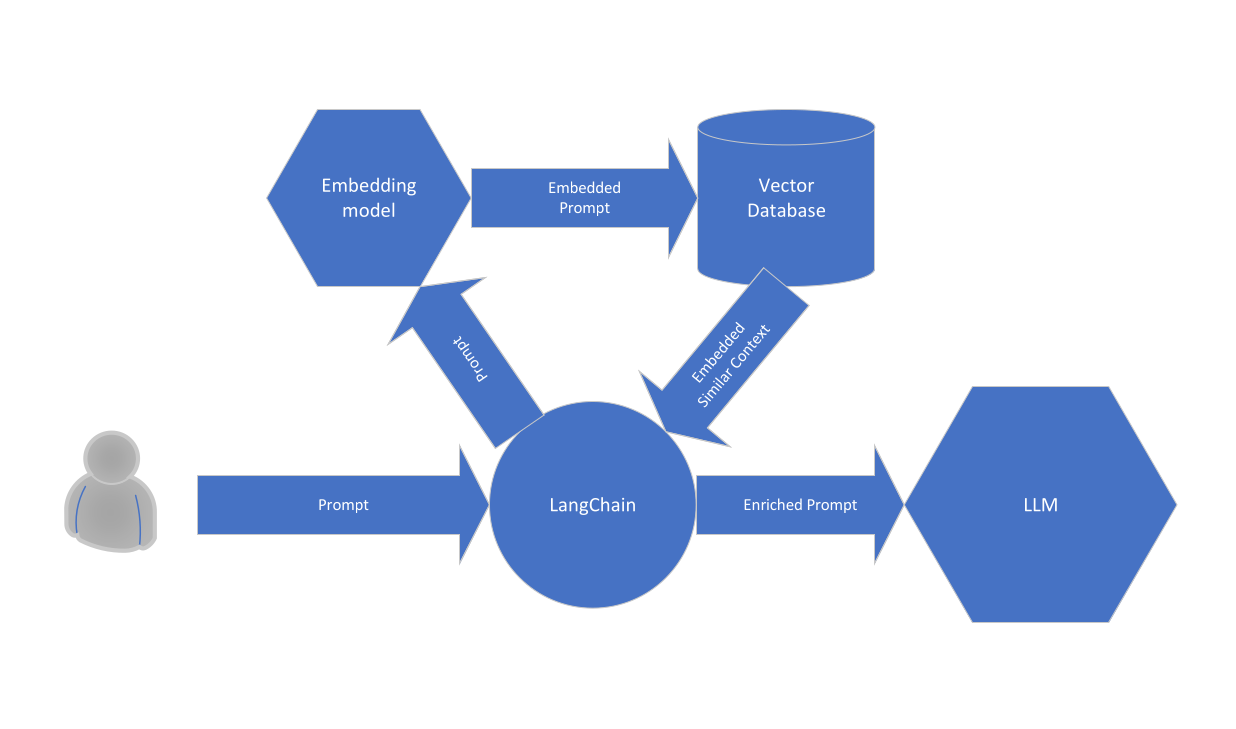
Onze van LLM afgeleide vector databasing use case
Een interne wiki (bijvoorbeeld Confluence) bevat alle informatie die een organisatie in de loop van de tijd opbouwt. Gedurende de dag worden nieuwe pagina’s aangemaakt en updates aan bestaande pagina’s doorgevoerd. Deze wijzigingen worden gemonitord door een embedding-generator die de embedding van de nieuw aangemaakte en bijgewerkte pagina’s berekent en deze Upsert naar Postgres (PGVector database). De OLTP-mechanismen maken een betrouwbare spiegeling van de staat van de wiki mogelijk. Onze LLM-applicaties willen de informatie van de wiki gebruiken, maar ik wil de context afbakenen tot specifieke kennisdomeinen. De embeddings die de kennisdomeinen definiëren, worden bewaard in parquet-bestanden die in het dataplatform zijn opgeslagen. De vectoren die in Parquet zijn opgeslagen, definiëren een kennisdomein waarop ik voor een bepaalde use case wil filteren. Het doel is om de ruis in de resultaten te verminderen bij het bevragen van de vector database op similariteit met de prompt van de gebruiker, door specifieke kennisdomeinen uit de interne wiki vooraf te selecteren. Om te integreren tussen de bedrijfsapplicatie (Postgres) en het dataplatform (parquet-bestanden) kies ik DuckDB. Naast dat het een uitstekende data-integratietool is, heeft DuckDB ook aangetoond analytisch werk te versnellen in vergelijking met het direct draaien van analytische queries op Postgres. Een eerdere blog verkent vergelijkbare integraties van PGVector en DuckDB. Ik wil deze aanpak uitbreiden met het nieuwe DuckDB Array Type en de context van onze voorgestelde use case.
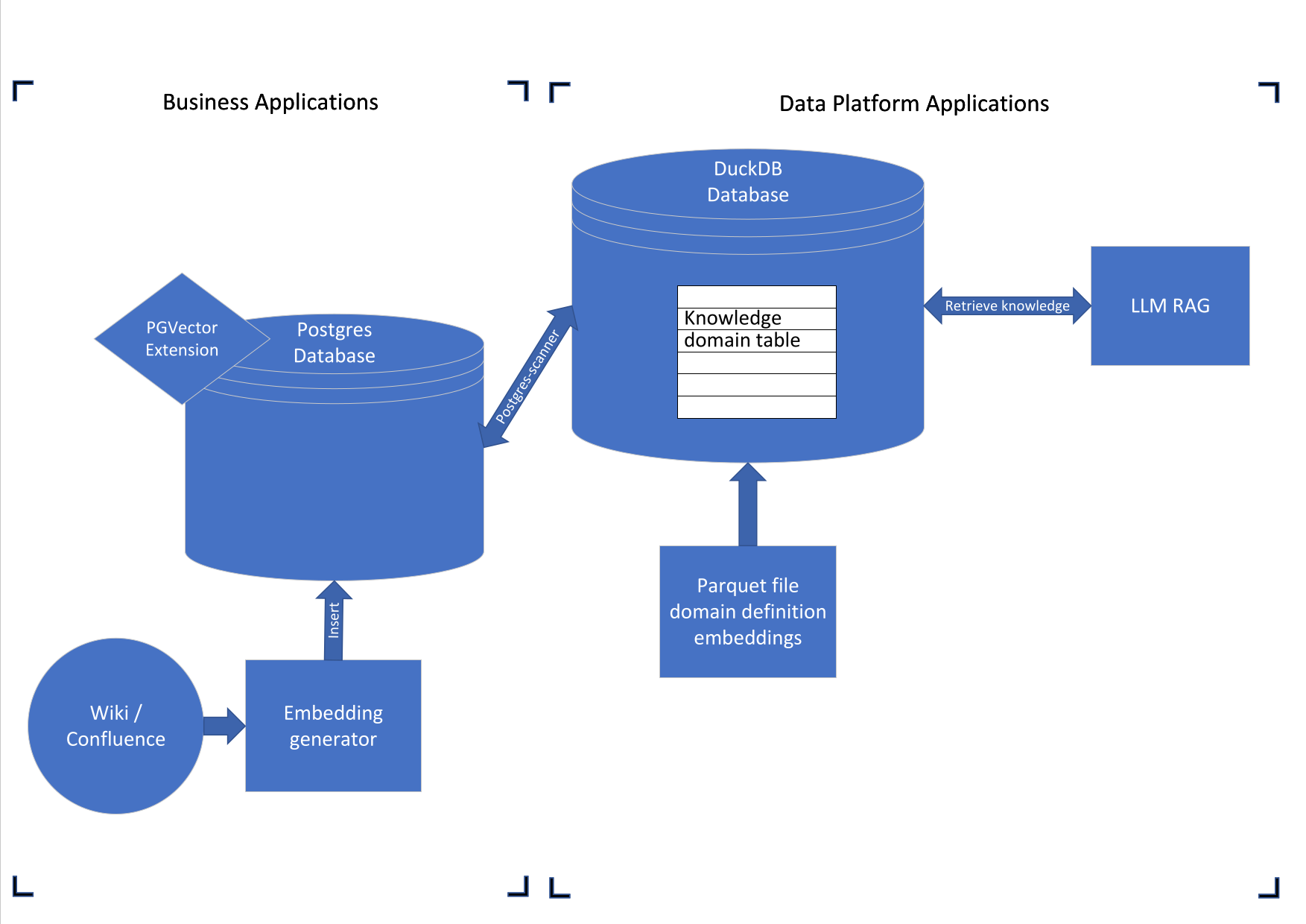
PGVector draaiend binnen de bedrijfsapplicatie
PGVector is een PostgreSQL-extensie voor efficiënte vectoropslag en -ophaling. Het voegt SQL-syntax toe voor het definiëren en opslaan van Vectoren en voor het ophalen op basis van similariteitsmetrieken. PGVector is ontworpen om te werken met hoogdimensionale vectoren, zoals die gebruikt worden in machine learning en data-analyse (tot 16000 dimensies). Het biedt functies voor vectorbewerkingen, zoals similarity search, nearest neighbour search en dot product-berekening. Approximate indexes kunnen worden toegevoegd om meer snelheid in te ruilen voor minder precieze en niet-deterministische resultaten. De transactionele aard van Postgres kan erg nuttig zijn wanneer je een stateful systeem zoals een interne Wiki aan het embedden bent en wilt dat de Vector database synchroniseert met live updates die op de Wiki worden gemaakt. Ik zie een embedding-model voor me dat triggert op events voor het aanmaken/bijwerken van wikipagina’s en de embeddings upsert naar Postgres, wat onderdeel is van de bedrijfsapplicatie.
PGVector Vector Type
Het Vector Type kan 16000 single precision Floats opslaan in één Vector-waarde en vectoren kunnen dus tot 16000 dimensies hebben. Uit de documentatie: “Each vector takes 4 * dimensions + 8 bytes of storage. Each element is a single precision floating-point number (like the real type in Postgres), and all elements must be finite (no NaN, Infinity or -Infinity). Vectors can have up to 16,000 dimensions”
DuckDB
DuckDB is een in-process analytisch database management system. Het streeft naar eenvoud, in navolging van het succes van SQLite. Het heeft geen externe dependencies, noch tijdens het compileren, noch tijdens runtime. Dit maakt DuckDB zeer portable en open voor allerlei architecturale patronen waarbij zeer verschillende systemen betrokken zijn. Er is API-ondersteuning voor Java, C, C++, Python, Go, Node.js en andere talen. DuckDB is desondanks rijk aan features en ondersteunt complexe queries, transactionele garanties, persistente opslag en is diep geïntegreerd met Python en R voor data-analyse. Ons doel voor DuckDB is om analyse van data mogelijk te maken met standaard SQL-queries, zonder de overhead van het kopiëren van de data naar een extern systeem of het vereisen van een gespecialiseerde query-interface. DuckDB is momenteel in ontwikkeling en dicht bij de 1.x-release (midden 2024). De 0.10-release komt binnenkort uit en is de belangrijke mijlpaal, die 1.x zal verharden en stabiliseren. 0.10 komt met het nieuwe fixed length Array Type dat zeer geschikt is voor Vectorbewerkingen en veel sneller is dan het bestaande List Type voor dergelijke toepassingen.
DuckDB aan Postgres koppelen
DuckDB kan momenteel direct queries draaien op Parquet-bestanden, CSV-bestanden, SQLite-bestanden, Pandas, R en Julia dataframes naast Apache Arrow-bronnen. Het is echt de spin in het web, waardoor gebruikers zijn analytische query-engine kunnen benutten die is afgestemd op de beste prestaties op kolomgeoriënteerde data. Dit is indrukwekkend voor een Database die binnen ons Python-proces draait en daarmee een minuscule footprint heeft qua configuratie en hosting.
Postgres-integratie
Het doel is om de hoogperformante analytische engine van DuckDB (OLAP) bovenop een Postgres (OLTP) database in te zetten in een productieomgeving. Nieuwe data stroomt vanuit bedrijfsprocessen Postgres in. Deze data kan dan direct voor analytics gebruikt worden. Om snelle en consistente analytische reads van Postgres-databases mogelijk te maken, is er een “Postgres Scanner” ontworpen. Deze scanner is gebaseerd op de binary transfer mode van het Postgres client-server protocol. Hierdoor kan DuckDB de data efficiënt transformeren en direct gebruiken, zonder dat de data hoeft te worden overgekopieerd. Er worden meerdere verbindingen geopend tussen DuckDB en Postgres om het scannen van tabellen en de verwerking daarvan te parallelliseren. Deze verbindingen worden gesynchroniseerd via een Postgres snapshotting-mechanisme, zodat de staat gesynchroniseerd en consistent is met de staat van de database op het moment dat de query werd afgevuurd.
Array Type
Nieuw in DuckDB 0.10.x is het fixed length Array Type. DuckDB had al hoogperformante geneste datatypes, waarvan de Array de nieuwste toevoeging is. Een Array wordt gedefinieerd door een base type op te geven en de fixed length integer tussen haakjes, zoals Float[10]. Er is een natuurlijke compatibiliteit tussen het PGVector Vector Type en een DuckDB Float Array.
PGVector Vectoren casten naar de DuckDB Arrays
Postgres stelt gebruikers in staat zijn typesysteem uit te breiden, zoals PGVector deed door het Vector Type toe te voegen. DuckDB kent deze user-defined types niet en representeert ze allemaal met het generieke VARCHAR type. Binnen DuckDB-queries en tabeldefinities moeten we de VARCHAR-representatie van het fixed length Vector Type casten naar een Array of Floats van dezelfde lengte. Deze cast heeft zeer weinig overhead, omdat het een andere interpretatie van dezelfde bytes is. Door deze cast uit te voeren maken we de Array-bewerkingen zoals cosine similarity binnen DuckDB mogelijk, gebaseerd op Postgres-data die vector embeddings bevat.
CAST(embedding as FLOAT[NDIM])
Proof-of-Concept
Hier volgt de PoC-code die de DuckDB-integratie met Postgres voor vector embeddings demonstreert. Voor het testen werd VSCode gedraaid met docker-compose devcontainers. Er werden twee containers opgestart, één voor python-ontwikkeling en één die Postgres met de PGVector-extensie draaide. Docker-compose koppelt de twee containers op hetzelfde netwerk, zodat we met Python requests naar de Postgres-database kunnen maken.
PGVector databasing
Postgres-database aanmaken
import psycopg
conn = psycopg.connect("postgresql://postgres:hack@localhost:5432", autocommit=True)
conn.execute("DROP DATABASE IF EXISTS vector")
conn.execute("CREATE DATABASE vector")
De Postgres Embeddings-tabel aanmaken
We schakelen eerst de vector-extensie in om het gebruik van het User Defined Type Vector in onze tabeldefinitie mogelijk te maken. Deze Vector is van een vaste lengte, wat verschilt van het standaard Postgres Array type. Deze lengte van de embedding wordt tijdens het aanmaken van de tabel gekozen, zoals hieronder getoond.
EMBEDDING_LENGTH = 1000
with psycopg.connect("postgresql://postgres:hack@localhost:5432/vector") as conn:
conn.execute("CREATE EXTENSION IF NOT EXISTS vector")
with conn.cursor() as cur:
cur.execute("DROP TABLE IF EXISTS embeddings")
cur.execute(
f"CREATE TABLE embeddings (id int, embedding vector({EMBEDDING_LENGTH}))"
)
Embeddings invoegen in de Postgres-tabel
Ik gebruik pgvector register_vector om een Postgres-verbinding te maken die zich bewust is van het Vector Type. De insert volgt standaard SQL. In de documentatie wordt string-interpolatie gebruikt om Vector-waarden in het INSERT-statement te interpoleren. Dit moet nadelen hebben bij het representeren van Floats. Iets dat openstaat voor nader onderzoek.
from pgvector.psycopg import register_vector
# Connect to an existing database
with psycopg.connect("postgresql://postgres:hack@localhost:5432/vector") as conn:
register_vector(conn)
embedding = np.arange(EMBEDDING_LENGTH)
conn.execute(
"INSERT INTO embeddings (id, embedding) VALUES (%s, %s)", (1, embedding)
)
# Make the changes to the database persistent
conn.commit()
Query en casting met DuckDB
Ik gebruik het zeer interactieve ‘duckdb.sql’-gebruik om de functionaliteit te verkennen en dit later te consolideren met meer correcte programmering na de 0.10.x-release. Met de 0.10-release verwachten we dat het Array type ondersteund wordt over de DuckDB-API’s heen, aangezien ik het in mijn dev build (0.9.3.dev3887) niet aan de praat kreeg in de ‘duckdb.connect()‘-verbindingsaanpak
Koppelen aan Postgres
Vrij recent heeft DuckDB de syntax van het ATTACH-statement verbeterd om verbinding te maken met Postgres. Je kunt een property meegeven om de verbinding read only in te stellen. Dit is nuttig in ons scenario waarin we koppelen aan een live systeem en de data in de bedrijfsapplicatie niet willen wijzigen.
duckdb.sql(
"ATTACH 'postgresql://<username>:<password>@localhost:5432/vector' AS postgres_db (TYPE postgres, READ_ONLY);"
)
Postgres direct bevragen
We bevragen de embeddings Postgres-tabel direct met DuckDB en in het select-statement casten we de Vector Type bytes naar een DuckDB fixed size Array of single precision Floats van de bijbehorende lengte.
duckdb.sql("SELECT id, CAST(embedding as FLOAT[EMBEDDING_LENGTH]) FROM postgres_db.public.embeddings")
Vector embeddings uit Parquet-bestand integreren
DuckDB maakt het direct bevragen van lokale en remote Parquet-bestanden mogelijk en ondersteunt gedeeltelijk lezen via zowel projection pushdown (kolomselectie) als filter pushdown (partities of zonemaps selecteren). Voor remote opslag is S3 goed ingeburgerd, terwijl Azure-ondersteuning momenteel experimenteel is. In de praktijk downloaden veel bedrijven eerst mappen met parquet-bestanden naar een lokaal bestandssysteem voordat ze deze met DuckDB bevragen. Gevolgd door het uploaden van de resultaten als parquet.
# Selecting all data directly from a local domain knowledge parquet file.
duckdb.sql("SELECT * FROM './data/default/domain_a.parquet';")
expliciete type casting, dus is het het beste om de embeddings naar VARCHAR te CASTen voordat je naar parquet schrijft. De omgekeerde cast naar een Array of Floats zou na het lezen uit het parquet-bestand moeten gebeuren.
Vector similarity query tussen Postgres en parquet
We willen de wikipagina-embeddings ophalen die relevant zijn voor ons gekozen kennisdomein. In de praktijk willen we wikipagina-vectoren in Postgres vinden die lijken op domeinkennis-vectoren die in Parquet zijn opgeslagen. Zo filteren we wiki-context uit het live systeem die binnen een kennisdomein ligt dat door het dataplatform is gedefinieerd. Twee direct query SELECT-statements (één die Postgres raakt en de andere die parquet raakt) worden gejoined op basis van de cosine similarity van de vectoren, met een threshold ingesteld op 0.7 (later te tunen). Cosine similarity is een van de meest gebruikte metrieken om de similariteit tussen twee vectoren te meten en heeft het voordeel dat het varieert van 0 (geen similariteit, orthogonaal) tot 1 (hoge similariteit en uitgelijnd) voor vectoren met positieve waarden. Het resultaat is dat embedded wikipagina’s die een sterke relatie met het kennisdomein hebben, geselecteerd worden.
duckdb.sql(
f"""--sql
SELECT DISTINCT embeddings.id, embeddings.embedding
FROM
(SELECT id, CAST(embedding as FLOAT[{EMBEDDING_LENGTH}]) AS embedding
FROM postgres_db.public.embeddings)
AS embeddings
JOIN
(SELECT id, CAST(embedding AS FLOAT[{EMBEDDING_LENGTH}]) AS embedding
FROM './data/default/domain_a.parquet')
AS domain_embeddings
ON (array_cosine_similarity(embeddings.embedding, domain_embeddings.embedding) > 0.7);
"""
)
Postgres-tabellen cachen in DuckDB
Wanneer een Postgres-tabel herhaaldelijk wordt gescand, kunnen we deze in het algemeen in DuckDB cachen om de prestaties te verbeteren met de CREATE TABLE
De domeinkennis-embeddings opslaan in een DuckDB-tabel voor RAG
De laatste stap voor ons is om de wikipagina-embeddings, gefilterd op het gekozen kennisdomein, te consolideren in een DuckDB-tabel zodat RAG-processen ze later kunnen bevragen.
# create domain knowledge table
duckdb.sql(
f"""--sql
CREATE TABLE domain_knowledge (id INT, embedding FLOAT[{EMBEDDING_LENGTH}]);"""
)
# insert query result into domain knowledge table
duckdb.sql(
f"""--sql
INSERT INTO domain_knowledge SELECT DISTINCT embeddings.id, embeddings.embedding
FROM
(SELECT id, CAST(embedding as FLOAT[{EMBEDDING_LENGTH}]) AS embedding
FROM postgres_db.public.embeddings)
AS embeddings
JOIN
(SELECT id, CAST(embedding AS FLOAT[{EMBEDDING_LENGTH}]) AS embedding
FROM './data/default/domain_a.parquet')
AS domain_embeddings
ON (array_cosine_similarity(embeddings.embedding, domain_embeddings.embedding) > 0.7);
"""
)
DuckDB als LangChain context retriever
We hebben de geselecteerde domeinkennis in een DuckDB-tabel ingevoegd voor gebruik in RAG-flows. Op dit moment ondersteunt LangChain, een populaire tool voor RAG, DuckDB alleen als document loader. Ik zou willen dat LangChain DuckDB gaat ondersteunen als Vector Store en zijn retriever-interface na de release van DuckDB 0.10.x of 1.x. Dit zou LangChain in staat stellen een snelle in-process database binnen RAG-applicaties te gebruiken voor lichtgewicht en snelle context-ophaling. De portabiliteit van DuckDB zou het mogelijk maken om RAG-applicaties met weinig overhead en infrastructuurvereisten uit te rollen.
Conclusie
DuckDB is een spin in het datalandschap met hoge portabiliteit en lage setup-kosten. De integratie met Postgres en het direct bevragen van parquet, samen met alle andere integraties en extensies, is indrukwekkend. Voor Vector databasing is het een geluk dat de binaire representaties van het PGVector Vector Type overeenkomen met een DuckDB Array of Floats, voor casting met lage overhead in zowel directe queries als tabelaanmaak. DuckDB maakt het mogelijk om meerdere bronnen van embedding-vectoren te combineren en samen te bevragen. Zo kunnen we ons Business platform Postgres integreren met parquet-bestanden die in ons dataplatform zijn opgeslagen. Ons doel is om de wiki-content te filteren op basis van kennisdomein-definities, om de betrouwbaarheid van RAG context-ophalingen te verbeteren. In onze voorgestelde architectuur wordt de klassieke kloof tussen OLTP- en OLAP-databases overbrugd. De mogelijkheid tot ontkoppeling wordt toegevoegd door DuckDB-tabellen te creëren die Postgres-tabellen cachen of query-resultaten opslaan. Na de release van het DuckDB Array type en bijbehorende functionaliteiten wacht ik op de bredere ondersteuning van DuckDB door LangChain voor RAG-flows.