Single-node en distributed Deep Learning op Databricks
Introductie
Databricks is een analytics-ecosysteem dat nu beschikbaar is op de meeste grote cloudproviders: Google, AWS en Azure. Databricks-clusterberekeningen gebruiken de Spark-engine en Python (PySpark), die enorm populair zijn voor analytics. De Python-interpreter draait meestal op de driver node om resultaten te verzamelen, terwijl de worker nodes JVM jar-bestanden uitvoeren. Nieuwe ontwikkelingen ondersteunen berekeningen op een driver zonder workers, maar waarom?
Single-node Databricks-clusters
De optie om single-node clusters te draaien is geïntroduceerd in oktober 2020 en wordt door alle Databricks-runtimes ondersteund. De Databricks Machine Learning Runtimes zijn goed samengesteld en werken meteen uit de doos. Je kunt kiezen voor GPU- of standaard CPU-runtimes en ze uitrollen op verschillende VM-formaten. De aankondiging van Databricks legt hun motivatie uit:
Standard Databricks Spark clusters consist of a driver node and one or more worker nodes. These clusters require a minimum of two nodes — a driver and a worker — in order to run Spark SQL queries, read from a Delta table, or perform other Spark operations. However, for many machine learning model training or lightweight data workloads, multi-node clusters are unnecessary.
Pandas DataFrames
Spark-commando’s worden in local mode op de driver uitgevoerd. Single-node clusters kunnen nog steeds Spark-databronnen gebruiken en de bijbehorende cloud-authenticatie/-autorisatie-ondersteuning, zoals ADLS authentication pass-through op Azure. Afgezien van data-extractie en het laden van data is Spark-functionaliteit niet zo nuttig op single-node clusters. Voor het trainen van een machine learning-model converteren we vaak van Spark naar Pandas DataFrames. Sinds Spark 2.3-2.4 zijn conversies van en naar Pandas versneld met arrow. Soms converteren we zelfs parquet (Data Lake) direct naar Pandas op Databricks, zie hieronder.

Een Azure use case
Laten we het hebben over het gebruik van single-node clusters in rekenpipelines. We willen meerdere DeepAR-modellen trainen, elk op een andere timeseries in onze dataset. Dit is embarrassingly parallel, omdat elk model getraind kan worden op een enkele CPU-VM met één timeseries in het geheugen. Elke trainingsjob staat gelijk aan het draaien van één Databricks-notebook, dat een specifieke timeseries importeert plus een Python-package met unit-geteste functionaliteit. We hebben honderden timeseries en zouden tientallen single-nodes willen opspinnen om onze trainingsjobs uit te voeren en onze modellen te registreren. We gebruiken Azure Data Factory om onze Databricks-notebooks in te plannen en clusters te starten (zie figuur hieronder).
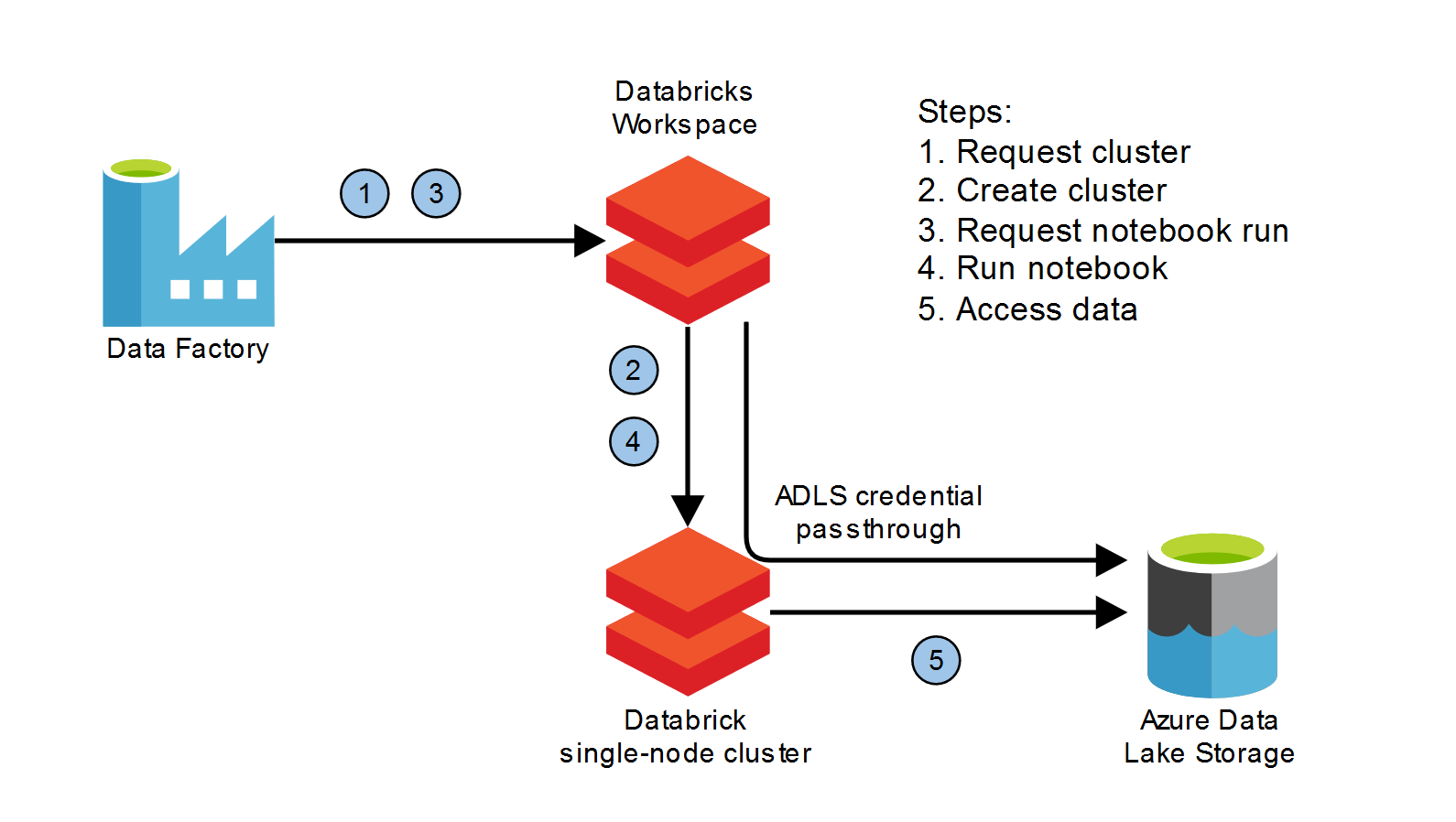
Parallelisme met Azure Data Factory
DataFactory-pipelines kunnen Databricks-notebooks parallel draaien en wachten tot ze klaar zijn voordat ze doorgaan naar de volgende activiteit van de pipeline. De ForEach-operator start een notebook voor elk element in een sequentie (bijvoorbeeld een data lake parquet-pad). Het kan in sequentie draaien of parallel met een batchgrootte. Zie ‘isSequential’ en ‘batchCount’ in de onderstaande Data Factory json-export. We starten 16 single-nodes die dezelfde Databricks-notebookactiviteit draaien om onze timeseries te verwerken. Data Factory beheert deze clusterresources via een Databricks linked service.

Databricks instance pool
Om een Databricks-notebook vanuit DataFactory te draaien, moeten we een linked service in DataFactory aanmaken. Er zijn drie manieren om de linked service te configureren om een Databricks-cluster te selecteren of aan te maken wanneer een notebookactiviteit wordt gestart.
- Interactive cluster is een al bestaand draaiend cluster dat we kunnen selecteren voor onze notebookactiviteiten.
- Job clusters worden voor elke gestarte notebookactiviteit aangemaakt. Het job cluster bestaat voor de duur van de notebookactiviteit. Dit kan leiden tot lange wachttijden voor clusteraanmaak en -beëindiging (tientallen minuten voor beide).
- Databricks instance pools zijn een configureerbaar aantal gereedstaande VM-instances die wachten tot ze in clusters worden opgenomen. De vertraging tussen idle en running is enkele minuten. Sinds eind 2019 ondersteund, zorgen instance pools voor een snelle doorlooptijd tussen jobs.
We maken een instance pool in Databricks aan met bijvoorbeeld 16 CPU-intensieve VMs naar keuze. Wanneer we onze Databricks linked service in DataFactory aanmaken, selecteren we deze instance pool en geven we een access token van de Databricks-workspace op. Wanneer een notebookactiviteit klaar is, worden de cluster-VM-instances teruggegeven aan de pool. De ForEach-operator kan tot 50 activiteiten parallelliseren, wat we beperken afhankelijk van de grootte van onze instance pool. De DF-pipeline mislukt als ons resource-verzoek groter is dan de grootte van de Databricks instance pool. Als we 20 notebookactiviteiten op single-nodes willen parallelliseren, hebben we een pool van 20 instances nodig. In dit geval doet Data Factory geen slim resourcebeheer.
Wordt vervolgd
Vervolgblogs over onze CICD-workflow voor Databricks-notebooks en de Data Factory-pipeline met de Python SDK zullen dieper op deze use case ingaan. In de volgende sectie vragen we ons af welk nut multi-node Databricks-clusters hebben als we Spark niet gebruiken voor modeltraining.
Distributed Deep Learning
We hebben de waarde gezien van single-node Databricks-clusters voor moderne machine learning. We draaien Databricks-notebooks op single-nodes met voldoende geheugen en GPU/CPU-resources. Laten we teruggaan en gedistribueerd rekenen overwegen. Zijn multi-node Databricks-clusters alleen nuttig voor Spark-berekeningen? Kunnen we een ander gedistribueerd rekenframework meeliften op de multi-node Databricks-clusters?
Databricks Horovod runner
Horovod (Uber) is een framework voor gedistribueerde deep learning met MPI en NCCL en ondersteunt TensorFlow, Keras, PyTorch en Apache MXNet. Spark-Deep-Learning van Databricks ondersteunt Horovod op Databricks-clusters met de Machine Learning Runtime. Het biedt een HorovodRunner die een Python Deep Learning-proces op meerdere workers binnen een Spark-task draait. Een Spark-task draait binnen een bestaande SparkContext op de worker (spark executor) en omvat een Python-runtime op de worker node, die communiceert met een coëxisterende JVM.
Gedistribueerde data gebruiken
Doorgaans gebruikt een gedistribueerde Horovod-optimizer gradient descent-berekeningen die tussen nodes worden gecommuniceerd met MPI. Data-extractie en preprocessing gebeurt binnen de Python-interpreter op de workers. Om trainingsresultaten te persisteren, wordt een checkpoint-directory op DBFS gebruikt om modelcheckpoints op te slaan door een van de workers, zie de beknopte code hieronder.
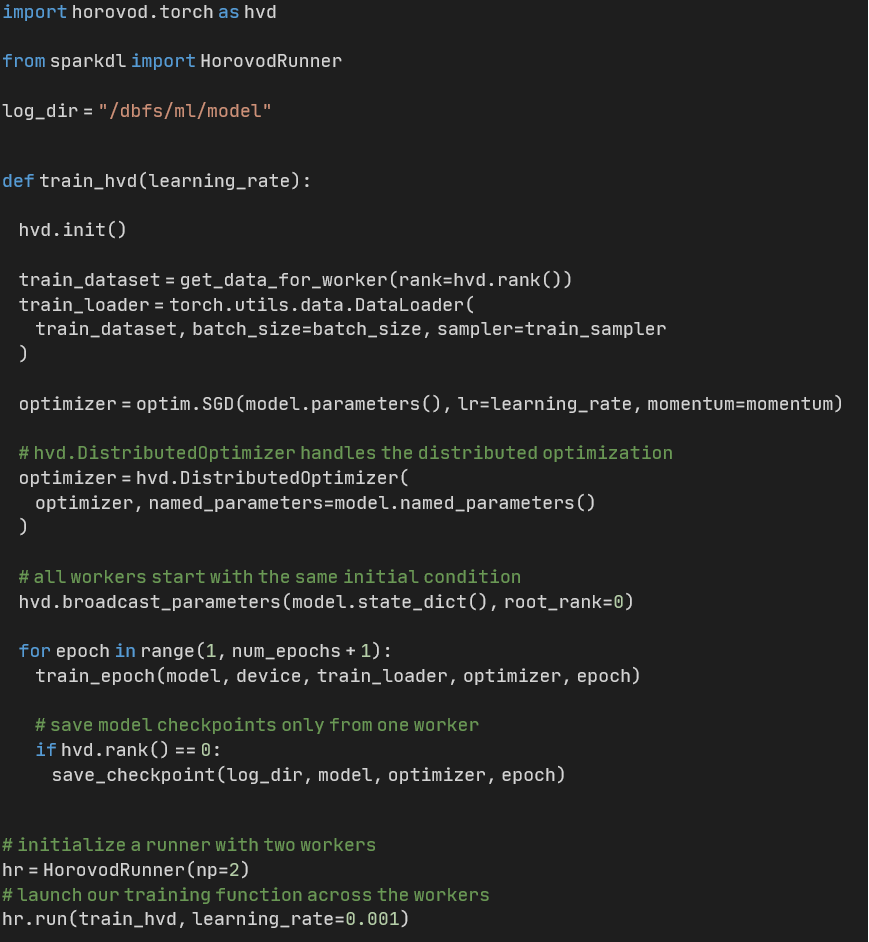
Bij het schrijven van Python-code voor de Horovod runner kunnen we geen Spark SQL-functionaliteit gebruiken om onze data te bevragen vanaf ons HDFS-achtige bestandssysteem. Alleen de Spark driver node kan deze functionaliteit coördineren en de resultaten verzamelen. Er zijn echter opties om vanuit HDFS-achtige data lake-opslag te lezen.
Petastorm (ook open source gemaakt door Uber) past bij onze behoeften. Deze library maakt het gebruik mogelijk van in een data lake opgeslagen Parquet-bestanden tijdens single-node en gedistribueerde training van deep learning-modellen. Het kan ook in-memory Spark DataFrames gebruiken. Petastorm converteert een gematerialiseerde Spark DataFrame naar een dataloader specifiek voor PyTorch en Tensorflow. Preprocessing-transformaties kunnen aan de Petastorm-converter worden toegevoegd als een TransformSpec, die op Pandas DataFrames werkt.
We kunnen Petastorm gebruiken voor gedistribueerde deep learning als we de ‘shard_count’ in de Petastorm-converter instellen op het aantal Horovod runners en Horovod de juiste shard laten selecteren op basis van de rank van de worker. We zorgen er ook voor om het onderliggende parquet-bestand te partitioneren naar het aantal Horovod-workers. Dit is geweldig! Gedistribueerde data op HDFS-achtige bestandssystemen kan worden ingezet voor gedistribueerde training van Deep Learning-modellen.
Toekomstige synergie via streaming
We hebben de integratie besproken van Horovod (Deep Learning) met het Databricks spark-cluster en Petastorm voor het laden van data. Hoe zou de Spark- en Horovod-integratie verbeterd kunnen worden? We zouden eenvoudiger datatransfer willen tussen de worker-JVM en de Python-interpreter op elke worker node. Arrow is precies de technologie en wordt al ondersteund. Eén oplossingsrichting zou Spark structured streaming kunnen zijn.
Structured Streaming-abstracties zijn gebaseerd op een continue DataFrame die groeit naarmate events binnenkomen vanuit streamingbronnen (bijvoorbeeld Kafka). Operaties worden uitgevoerd in micro-batches of continu met drie outputformaten (Append, Update, Complete). De PySpark API loopt achter op de Java/Scala API en ondersteunt geen arbitraire operaties met of zonder state. Prestatiebeperkingen zijn deels de reden waarom de PySpark structured streaming API geen arbitraire operaties ondersteunt en zich richt op Spark SQL-aggregaties.
Wishlist: arbitraire PySpark streaming-operaties
Tijdens het trainen vertegenwoordigt ons DL-model state die we bij elke trainingsstap willen bijwerken. De Python UDF die aan de HorovodRunner wordt doorgegeven, is een stateful operatie op een batch data. Bijvoorbeeld het trainen van een DNN op elke afbeelding in een dataset. We zouden elke afbeelding vanuit HDFS naar het Python-proces kunnen streamen met Spark Structured Streaming, net op tijd voor de training. De niet-functionele code hieronder geeft enig idee hoe het eruit zou zien.
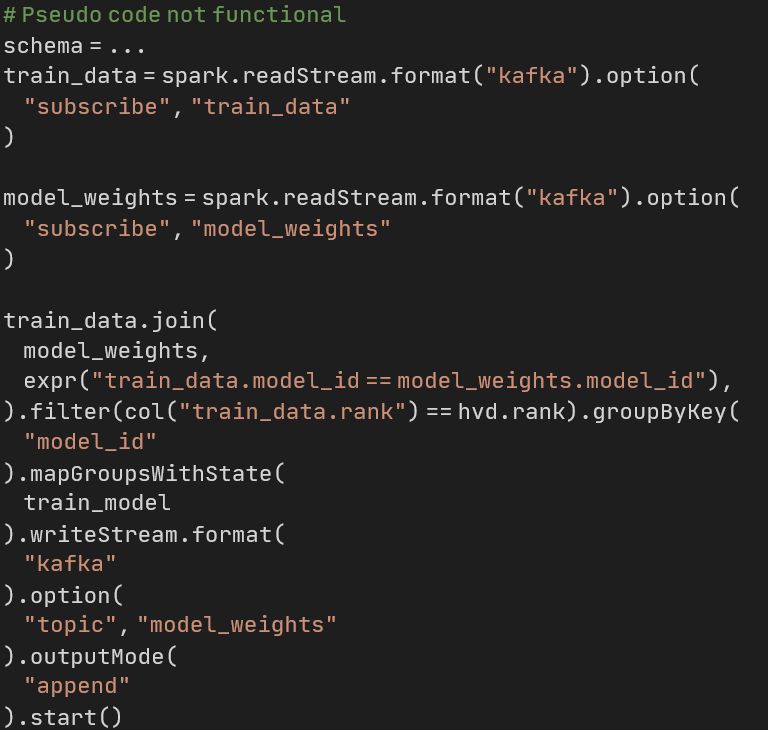
Afronding
Deze blog draaide om niet-Spark-centrische toepassingen van Databricks-clusters. We gingen van het parallel draaien van Deep Learning-training op single-node clusters naar het draaien van gedistribueerde training op multi-node clusters. Onze focus lag op het beschrijven van het gebruik van gedistribueerde data voor onze modeltraining en het voorstellen van enkele manieren om de kloof te dichten tussen data- en rekenintensieve toepassingen van Spark/Databricks-clusters. In vervolgblogs bespreken we in meer detail hoe we CICD aanpakken met Databricks-notebooks en Data Factory-pipelines.