MLOps: een verhaal van twee Azure-pipelines
Doel
MLOps wil verse en betrouwbare AI-producten leveren door middel van continuous integration, continuous training en continuous delivery van machine learning-systemen. Wanneer er nieuwe data beschikbaar komt, werken we het AI-model bij en deployen we het (als het verbeterd is) automatisch met DevOps-practices. Azure DevOps-pipelines ondersteunen dergelijke practices en zijn ons platform van voorkeur. AI of Machine Learning is echter gericht rond AzureML, dat zijn eigen pipeline- en artifactsysteem heeft. Ons doel is om DevOps-pipelines te combineren met AzureML-pipelines in een end-to-end MLOps-oplossing. We willen continu modellen trainen en ze conditioneel deployen op onze infrastructuur en applicaties. Meer specifiek is ons doel om continu een PyTorch-model bij te werken dat in een Azure function draait.
Overzicht van de oplossing
Het volgende diagram toont onze beoogde oplossing. Bovenaan staan drie triggers. Wijzigingen aan de infrastructure-as-code triggeren de Terraform-infrastructuurpipeline. Wijzigingen aan de Python-code van de function triggeren de Azure function deploy-pipeline. Tot slot triggert nieuwe data op een schema de model-trainingspipeline, die een conditionele deploy van de function met het nieuwe model doet als het nieuwe model beter is.
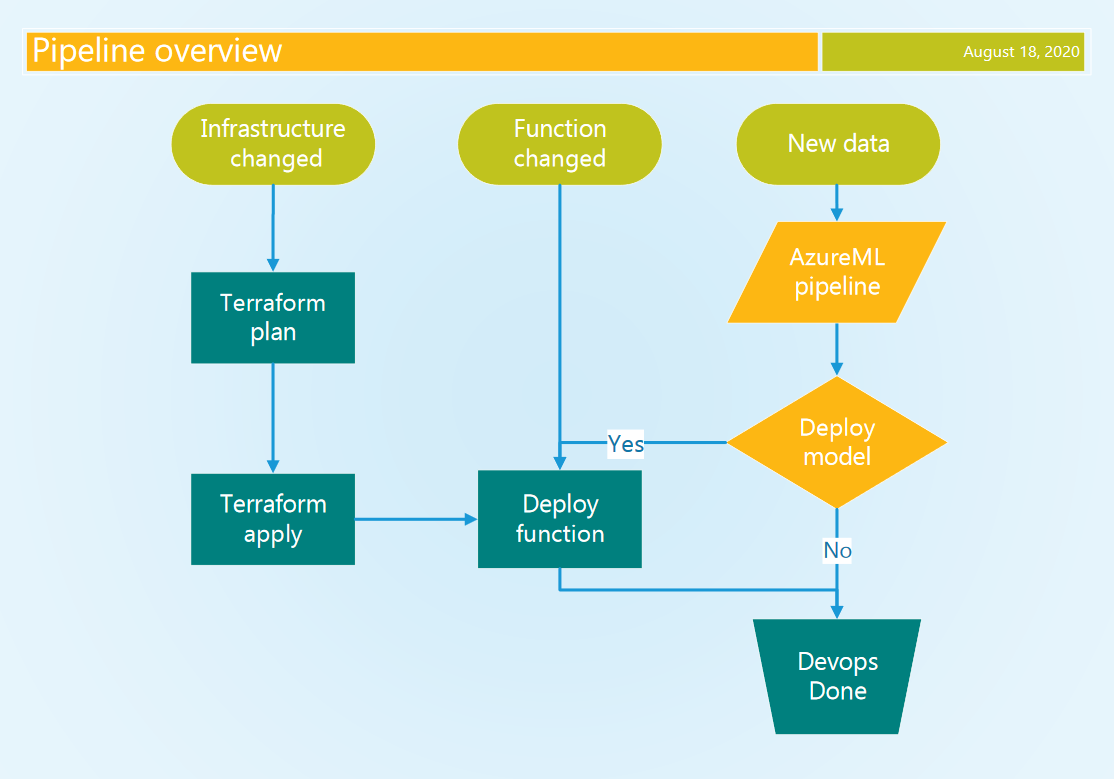
1 DevOps-infrastructuurpipeline
Binnen een DevOps-pipeline kunnen we vrijwel elk aspect van de Azure-cloud organiseren. Ze maken herhaalbare en reproduceerbare infrastructuur- en applicatie-deployment mogelijk. Enkele van de belangrijkste features zijn:
- Ondersteuning om vrijwel alle Azure-services te automatiseren
- Uitstekend secret management
- Integratie met Azure DevOps voor samenwerking en planning binnen het team
1.1 Pipeline jobs, steps en tasks
DevOps-pipelines worden geschreven in YAML en hebben verschillende mogelijke organisatieniveaus: stages, jobs, steps. Stages bestaan uit meerdere jobs en jobs bestaan uit meerdere steps. Hier richten we ons op jobs en steps. Elke job kan een conditie voor uitvoering bevatten en elke step bevat een task die specifiek is voor een bepaald framework of service. Bijvoorbeeld een Terraform-task om infrastructuur te deployen of een Azure KeyVault-task om secrets te beheren. De meeste tasks hebben een service connection nodig die gekoppeld is aan ons Azure-abonnement om toegang te krijgen tot onze resources en deze te mogen wijzigen. In ons geval gebruiken we de authenticatie die door de Azure CLI-task wordt gedaan om Python-scripts uit te voeren met de juiste credentials om met onze AzureML-workspace te interacteren.
1.2 Infrastructure as code
Er zijn goede argumenten om tools zoals Terraform en Azure Resource Manager te gebruiken om onze infrastructuur te beheren, die we hier niet zullen herhalen. Belangrijk voor ons: deze tools kunnen herhaaldelijk vanuit onze DevOps-pipeline gestart worden en leiden altijd tot dezelfde resulterende infrastructuur (idempotentie). Zo kunnen we de infrastructuurpipeline vaak starten, niet alleen wanneer er wijzigingen in de infrastructure-as-code zijn. We gebruiken Terraform om onze infrastructuur te beheren, wat de juiste service connection vereist.
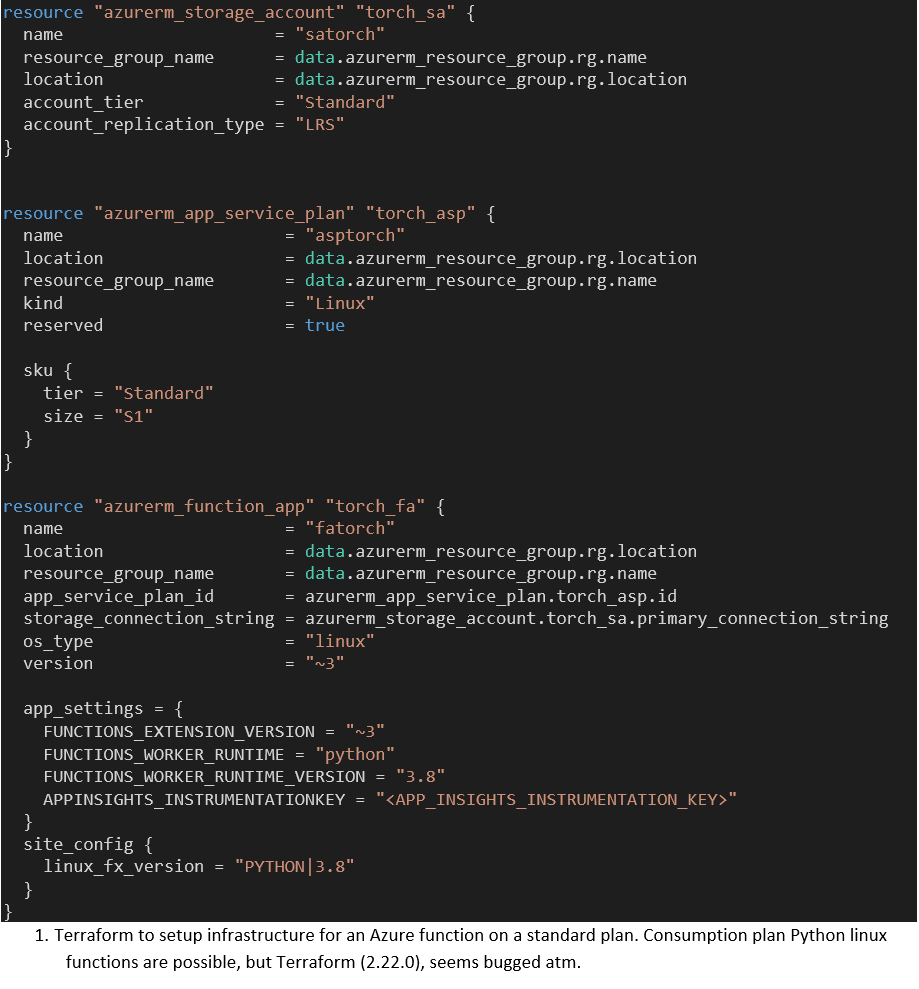
De volgende Terraform-definitie (Code 1) maakt een function app service aan met het bijbehorende storage account en Standard app service plan. We hebben deze opgenomen omdat het Linux-voorbeeld uit de documentatie voor ons niet werkte. Voor volledige serverless-voordelen konden we deployen op een consumption plan (elastic), maar de azurerm-provider voor Terraform lijkt een storende bug te hebben die ons verhinderde dit hier op te nemen. Voor de beknoptheid hebben we de DevOps-pipelinestappen voor het toepassen van Terraform niet opgenomen en verwijzen we naar de documentatie.
2 AzureML-pipeline
AzureML is een van de manieren om datascience op Azure te doen, naast Databricks en het legacy HDInsight-cluster. We gebruiken de Python SDK voor AzureML om onze pipelines te maken en uit te voeren. Het opzetten van een AzureML-ontwikkelomgeving en het draaien van trainingscode op AMLCompute-targets leg ik hier uit. In deel 2 van die blog beschrijf ik de AzureML Environment en Estimator, die we in de volgende secties gebruiken. De AzureML-pipeline combineert preprocessing met estimators en verbindt ze met PipelineData-objecten.
Enkele voordelen zijn:
- Reproduceerbare AI
- Hergebruik van data-preprocessingstappen
- Beheer van data-afhankelijkheden tussen stappen
- Registreren van AI-artifacts: model- en dataversies
2.1 Pipeline-creatie en steps
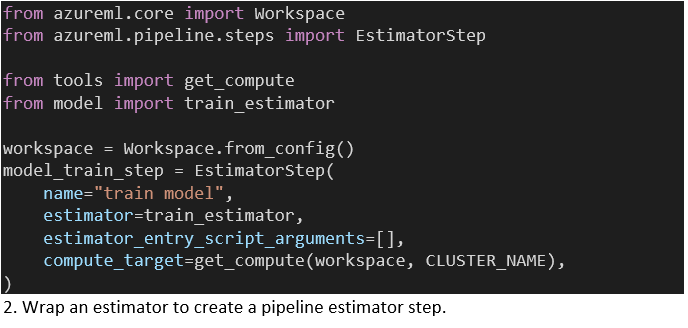
Onze Estimator omvat een PyTorch-trainingsscript en geeft command line-argumenten daaraan door. We voegen een Estimator toe aan de pipeline door deze te wrappen met de EstimatorStep-klasse (Code 2). Om een AzureML-pipeline te maken moeten we de Experiment-context en een lijst van steps die in volgorde uitgevoerd worden meegeven (Code 3). Het doel van onze huidige Estimator is om een bijgewerkt model te registreren bij de AzureML-workspace.

2.2 Model-artifacts
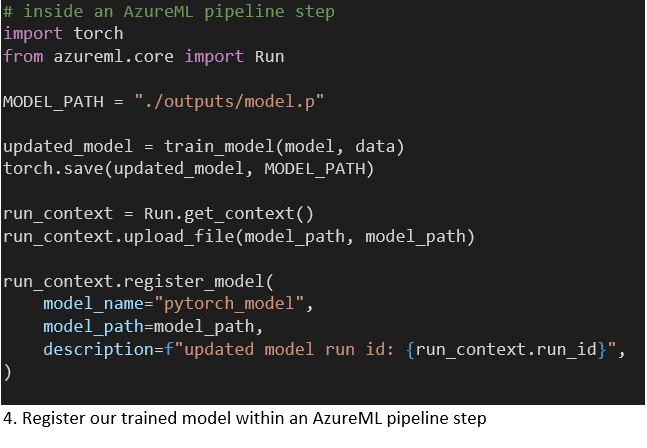
PyTorch- (en andere) modellen kunnen geserialiseerd en geregistreerd worden bij de AzureML-workspace met de Model-klasse. Het registreren van een model uploadt het naar gecentraliseerde blob storage en maakt het mogelijk om het, verpakt in een Docker-container, te publiceren naar Azure Docker instances en Azure Kubernetes Service. We wilden het simpel houden en de AzureML-modelregistratie behandelen als artifact storage. Onze estimator step laadt een bestaand PyTorch-model en traint het op de nieuw beschikbare data. Dit bijgewerkte model wordt elke keer dat de pipeline draait onder dezelfde naam geregistreerd (code 4). De modelversie wordt automatisch opgehoogd. Wanneer we ons model ophalen zonder een versie op te geven, pakt het de nieuwste versie.
3 AzureML- en DevOps-pipelines combineren
3.1 DevOps-pipeline-centrische architectuur
In onze aanpak van MLOps / Continuous AI is de DevOps-pipeline leidend. Die heeft beter secrets management en bredere mogelijkheden dan de AzureML-pipeline. Wanneer er nieuwe data beschikbaar is, start de DevOps-pipeline de AzureML-pipeline en wacht tot deze klaar is, met een conditionele beslissing of het model gedeployd moet worden. Deze beslissing is gebaseerd op de prestaties van het model vergeleken met het vorige beste model. We plannen de model-pipeline op vaste intervallen wanneer er nieuwe data wordt verwacht met de cron trigger.
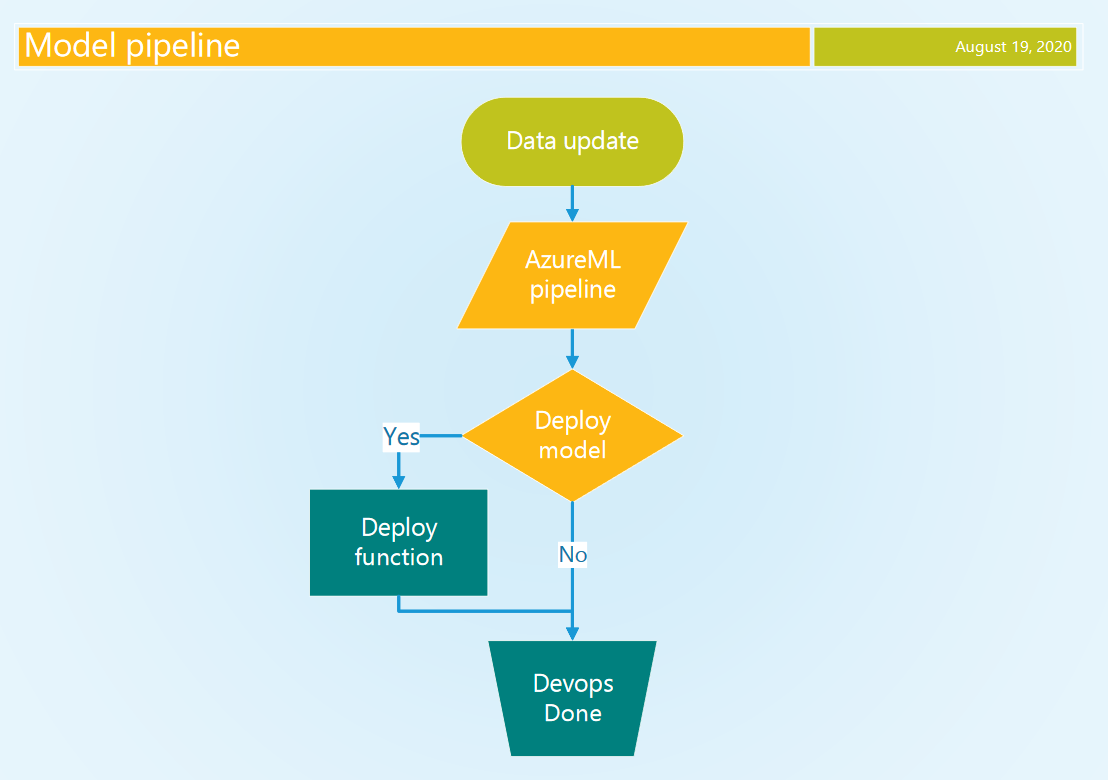
3.2 AzureML starten vanuit DevOps
Een Azure CLI-task authenticeert de task met onze service connection, die toegang heeft tot onze AzureML-workspace. Deze toegang wordt door het Python-script gebruikt om de Workspace- en Experiment-context te maken, zodat we de Pipeline met de AzureML SDK kunnen draaien. We wachten tot de AzureML-pipeline klaar is, met een instelbare timeout. Deze timeout wordt door Azure DevOps beperkt tot 2 uur. De implicaties hiervan worden aan het einde van de blog besproken.
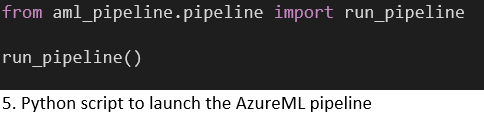
Er wordt een basaal Python-script getoond (Code 5) dat de AzureML-pipeline in Code 3 aftrapt. Dit script wordt gestart vanuit een AzureCLI-task (Code 6) voor de vereiste authenticatie. Let op: het is niet ideaal dat we een account met rechten op het niveau van het Azure-abonnement nodig hebben om met AzureML te interacteren, zelfs voor de meest basale operaties, zoals het downloaden van een model.

3.3 Conditionele model-deployment in DevOps
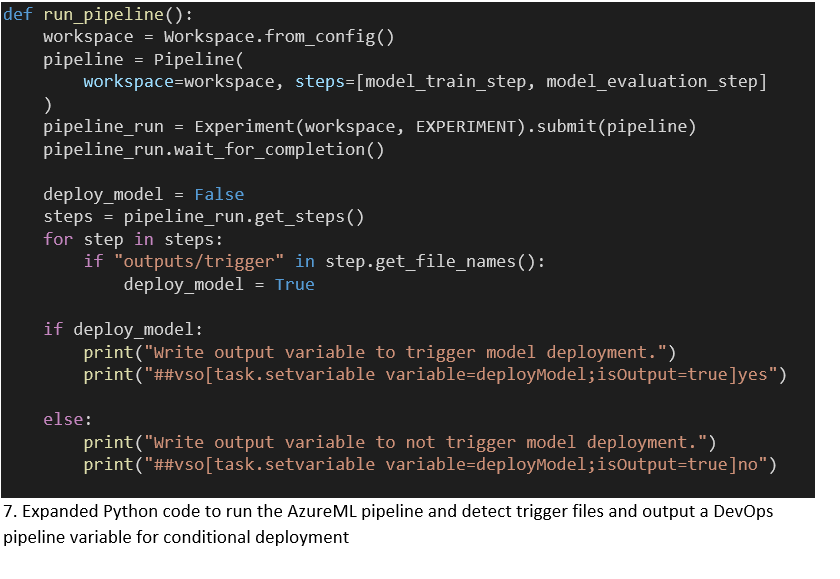
Een bijgewerkt model dat getraind is met de nieuwste data zal per definitie niet beter presteren. We willen op basis van de prestaties beslissen of we het nieuwste model deployen. We willen dus onze intentie om het model te deployen vanuit AzureML communiceren naar de DevOps-pipeline. Om een variabele naar de DevOps-context te schrijven, moeten we een specifieke string naar de stdout van ons Python-script schrijven.
In onze implementatie kan elke step in de AzureML-pipeline een deployment triggeren door het volgende lokale lege bestand “outputs/trigger” aan te maken. De “outputs”-directory is speciaal en Azure uploadt automatisch naar de centrale blob storage, toegankelijk via het PipelineRun-object en de ML studio. Nadat de AzureML-pipeline klaar is, inspecteren we alle steps in de PipelineRun om te zien of er een triggerbestand is aangemaakt. Gevolgd door het schrijven van een variabele naar de DevOps-context als een Task output-variabele.
4 Model en code deployen naar een Azure function
4.1 Conditionele DevOps-deploy-job
We hebben een nieuw model getraind en willen het deployen. We hebben een DevOps-job nodig die de deployment verzorgt, die conditioneel draait op basis van de output van onze AzureML-trainingspipeline. We kunnen de hierboven beschreven output-variabele benaderen en een gelijkheidscheck uitvoeren binnen de condition-clausule van de job. Code 8 hieronder laat zien hoe we de task output-variabele uit de vorige train-job benaderen in de conditie van de deploy-job.

4.2 De nieuwste modelversie ophalen
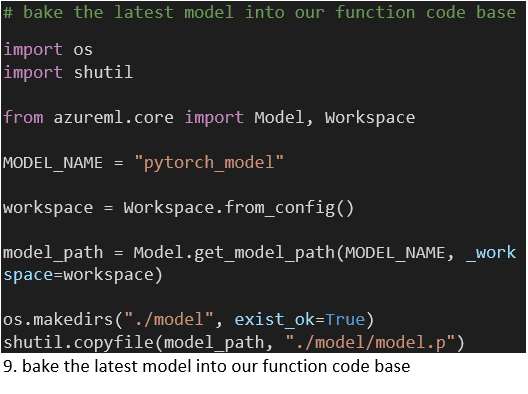
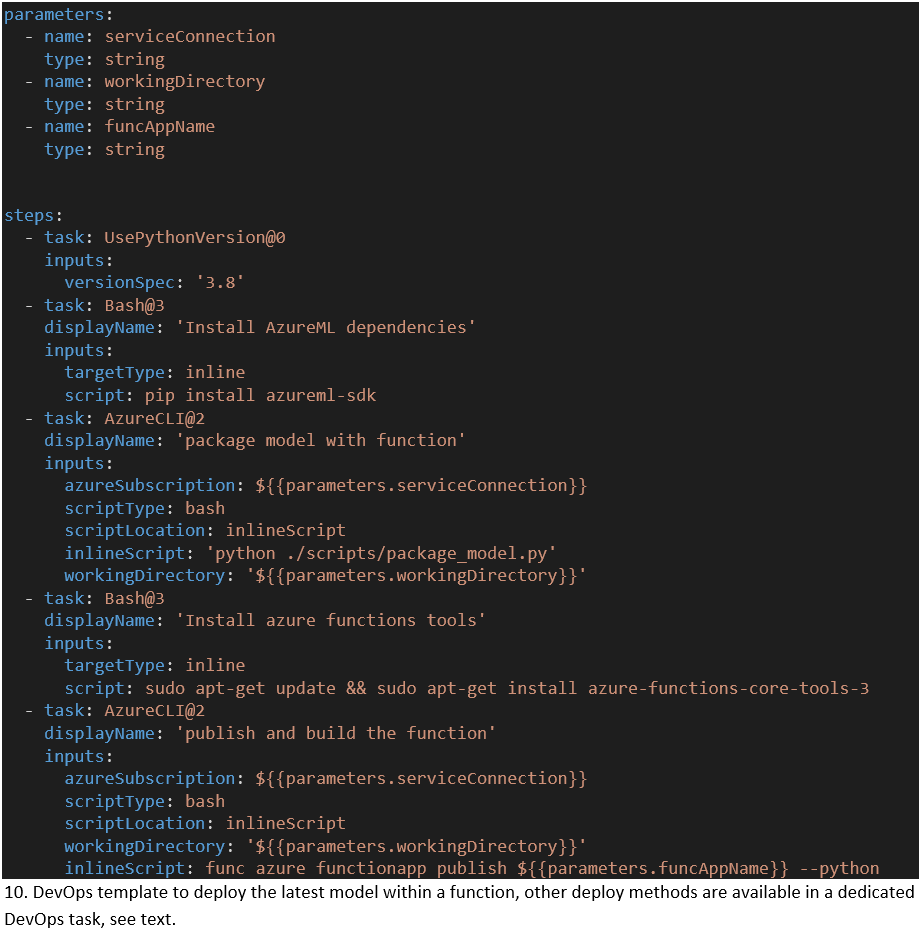
Om het nieuwste model uit de AzureML-workspace op te halen gebruiken we een Azure CLI-task om de vereiste authenticatie af te handelen. Daarbinnen draaien we een Python-script dat zich aan onze Workspace koppelt en het model downloadt naar een directory binnen de directory die onze function-code bevat (Code 9). Wanneer we onze function deployen, wordt dit script aangeroepen om ons model samen met onze Python-code en requirements te bundelen (Code 10, task 3). Elke modelrelease impliceert dus een function deploy.
4.3 Model en code deployen naar onze function app
De azure-functions-core-tools ondersteunen lokale ontwikkeling en deployment naar een Function App. Voor onze deployment wordt de function build agent gebruikt om de Python-requirements te installeren en het package naar de Function App te kopiëren. Er is een speciale DevOps-task voor function-deployments die je kunt verkennen. Voor nu hadden we een betere ervaring met het installeren van de azure-functions-core-tools op de DevOps build agent (ubuntu) en het publiceren van onze function daarmee (Code 10, step 5).
Discussie
In deze blog presenteren we een pipeline-architectuur die Continuous AI op Azure ondersteunt met een minimaal aantal bewegende delen. Andere oplossingen die we tegenkwamen voegen Kubernetes of Docker Instances toe om de AzureML-modellen te publiceren voor gebruik door frontend-gerichte functions. Dat is een optie, maar het kan de engineering-belasting van je team verhogen. We denken wel dat het toevoegen van Databricks onze workflow kan verrijken met collaboratieve notebooks en meer interactieve modeltraining, vooral in de exploratiefase van het project. De AzureML-MLFlow-API stelt je in staat om een model vanuit Databricks-notebooks te registreren en op dat punt in onze workflow in te haken. Later in het project, met het model dat al een tijd in productie draait, kan een AzureML-pipeline meer zin hebben als platform voor het regelmatig bijwerken van het model.
Volledige modeltraining
Onze focus ligt op modeltraining voor incrementele updates met trainingstijden van uren of minder. Wanneer we volledige modeltraining overwegen, gemeten in dagen, kan de pipeline-architectuur worden uitgebreid om non-blocking processing te ondersteunen. Eén optie is om het draaien van de AzureML-pipeline te doen met Azure Datafactory, dat geschikter is voor langlopende orkestratie van data-intensieve jobs. Als het getrainde model levensvatbaar wordt geacht, kan een vervolg-DevOps-pipeline getriggerd worden om het te deployen. Een low-tech trigger-optie (met beperkte authenticatie-opties) is het http-endpoint dat aan elke DevOps-pipeline gekoppeld is.
Use cases
AI is niet de enige use case voor onze aanpak, maar wel een belangrijke. Verwante use cases zijn interactieve rapportage-applicaties die op streamlit draaien en die representaties van kennis kunnen bevatten die bijgewerkt moeten worden. Machine learning-modellen, interactieve rapporten en feiten uit de datalake werken samen om management of klant te informeren en tot actie te leiden. Bedankt voor het lezen.