EuroPython 2022: Samenvattingen van geselecteerde talks
Dag 1
Python’s role in unlocking the secrets of the Universe with the James Webb Space Telescope
keynote-spreker: Dr. Patrick Kavanagh
De eerste James-beelden zijn deze week vrijgegeven. 90% van de analysetaken wordt met Python uitgevoerd. James is een pure infraroodtelescoop met een grote spiegel om de vroegste sterren in het universum te vinden. Als je warmte wilt waarnemen, moet je de telescoop heel koud houden. Gelanceerd op 25 december 2021, de slechtste kerstdag ooit, vanwege de spanning. Ariadne heeft uitstekend werk geleverd door de brandstof op de satelliet te besparen, waardoor de verwachte levensduur van 10 naar 20 jaar werd verlengd.
Beelden hebben behoorlijk wat bewerking nodig om de mooie eindresultaten te krijgen, vanwege detectoreffecten. We moeten alle telescoop- en detectoreffecten verwijderen. Dit is het belangrijkste doel van de instrumentteams die een datapipeline gebruiken die de calibratiepipeline wordt genoemd. Een reeks stappen om artefacten sequentieel te verwijderen. Artefacten worden verwijderd op basis van calibratiebestanden die handmatig samengesteld en incrementeel verbeterd worden.
Alles is gebouwd in Python in een privé-github-repo om het Miri-instrument in gebruik te nemen, en het proces voor de andere instrumenten is hetzelfde. Je wilt niet dat alle wetenschappers deze calibratie en filtering doen. We leveren een python science software package dat 17 science modes ondersteunt, gedetecteerd op basis van image-metadata. Deze automatische pipeline heet de JWST calibration pipeline, geïmplementeerd met Python (met C-plugins), en is publiekelijk beschikbaar.
Waarom Python? Er is veel ervaring met python in de astrofysica-gemeenschap. Het is makkelijker te onderhouden over instrumenten heen door hetzelfde framework te hergebruiken. Modulaire opbouw via Python-classes. Open ontwikkeld. Offline pipeline-ondersteuning om op je eigen machine te draaien voor debugging en development, met ondersteuning voor pauzeren en opnieuw uitvoeren. Data opgeslagen in de FITS-standaard met veel metadata over de observatie. Het biedt ontwikkelaars een gemeenschappelijk framework voor steps/pipelines. Dit alles is gebaseerd op stpipe (python package). We hebben classes voor pipeline step en pipelines. handelt alles af op basis van de metadata in de ruwe data, data-in en -output, ophalen van calibratiebestanden, verwijderen van artefacten, logging, enz.. Datatransformatie is geïmplementeerd in een aparte methode in de step-class, die wordt geïmplementeerd door toegewezen wetenschappers. Alle overige dataverwerking en het laden van data wordt buiten deze methode afgehandeld, geïmplementeerd door engineers.
We moesten onze pipeline testen met relevante testdata. Hiervoor hadden we simulators nodig om representatieve ruwe data te maken. Dit werd allemaal in Python gedaan. Het doel was om de observatie van een bekend hemellichaam te reconstrueren op basis van gesimuleerde data.
Biden onthulde het diepste beeld van een deel van het sterrenveld, vastgelegd in 12 uur vergeleken met weken voor Hubble. Het toont gravitatielenswerking op een melkwegstelsel. een melkwegstelsel van 13 miljard lichtjaar geleden. Er zijn melkwegstelsels zichtbaar die ook op Hubble-foto’s zichtbaar zijn, vanwege hun afstand en roodverschuiving. De verschillende instrumenten ondersteunen elkaar, waarbij MIri de dynamiek op zeer lange golflengte van interstellair medium en vroege melkwegstelsels doet.
Making Python better one error message at a time
spreker: Pablo Galindo Salgado (Python core developer)
Syntaxfouten worden getoond op regels waar de fout niet veroorzaakt is. Meestal wijst het naar een regel verderop dan waar de syntaxfout is gemaakt. Bijvoorbeeld “SyntaxError: unexpected EOF while parsing”. Hoe leg je dat uit? We moeten dit verbeteren in de interpreter om huidige en nieuwe gebruikers te ondersteunen. Laat me je enkele van de verbeteringen tonen die we hebben gemaakt. We hebben de complete parser vervangen en de nieuwe heet PEG parsers, die 30 jaar nieuwer is dan de oude LL(1)-parser uit 1990. De vervanging door de nieuwe parser leverde nieuwe grammatica op, zoals het “match”-statement, dat populairder is dan reddit je zou doen geloven. De PEG-parser is niet inherent slecht; ik wil laten zien dat je coole dingen kunt doen met de parser, zoals het verbeteren van de foutmeldingen.
Bijvoorbeeld, als je een ontbrekende kolom hebt om een blok af te sluiten of je mist een waarde in een dictionary, dan geven deze nu contextuele SyntaxErrors met foutmeldingen die hout snijden, in plaats van vreemde, verkeerd geplaatste SyntaxErrrors. Dus iedereen wint. Het toevoegen van deze foutmeldingen is moeilijk :( Als mens weet je wat je wilt doen, maar de parser probeert te begrijpen wat je wilt schrijven en kan dit uitbreiden tot het raden van wat je wilt doen. Dit raden is erg lastig, bovenop de uitdaging om in het algemeen goede foutmeldingen te genereren.
x = [x, y z, w]
>> SyntaxError: Perhaps you forgot a comma
Een simpele matching-regel werkt niet, want een ontbrekende waarde in een dictionary zou ook “Perhaps you forgot a comma” printen. Net als veel andere edge cases, plus de match case loopt vast omdat die twee namen heeft die door een spatie gescheiden zijn. Hier is mijn issue tracker, die laat zien dat ik op de harde manier heb geleerd dat regels voor foutmeldingen lastig zijn. De syntaxchecker werd ook traag in edge cases met exponentiële backtracking op geneste haakjes.
Nu we veel SyntaxErrors hebben afgedekt, verleggen we onze aandacht naar Runtime suggestions. Runtime suggestions zijn fouten en problemen die tijdens runtime worden gedetecteerd. Vergelijkingen met Rust zijn niet eerlijk, omdat de meeste van hun foutmeldingen tijdens compile time in plaats van runtime worden gegenereerd. In Python, als je een attribuut op een Tuple wilt benaderen, stelt het voor om een NamedTuple te gebruiken. Hetzelfde geldt voor toegang tot niet-bestaande objectattributen. De uitdaging is om deze fouten alleen te genereren als de gebruiker daadwerkelijk een fout heeft gemaakt, in plaats van bij verwacht gedrag waarbij een AttributeError wordt opgevangen en doorgegeven. Anders zou het de code-uitvoering erg traag maken in normale, verwachte gevallen. De manier waarop we het doen: er is een functie print_exception wanneer een exception zich op het hoogste niveau bevindt zonder handlers. Deze C-functie doet een aantal stappen, waaronder het printen van exception-suggesties. In dat stadium kunnen we wat meer tijd nemen om onze berekening te doen.
Een gerelateerde verbetering zijn betere, gedetailleerde meldingen bij complexe Python-expressies waarbij een van de objecten None is, maar je niet weet welke. Dit was vroeger totaal onduidelijk en je moest raden. Nu hebben we duidelijke foutmeldingen en wijzen we het object aan dat van het type NoneType is. Om dit te doen gebruiken we Binary code instructions. Wanneer de fout optreedt, extraheren we de code die de fout veroorzaakt. We hebben er hard aan gewerkt om posities in de code te produceren door de positie te vinden van de instructie die faalt en de broncodepositie te reconstrueren op basis van de binaire instructies. Deze broncodeposities worden in de foutmeldingen geprint om een goed idee te geven waar de fout vandaan komt.
Hoe kunnen mensen ons helpen de interpreter slimmer te maken? We hebben een guide to CPython’s Parser; die is niet voor iedereen, maar legt uit hoe je nieuwe grammatica’s toevoegt en hoe de nieuwe PEG-parser werkt. Het legt ook uit hoe je nieuwe foutmeldingen kunt toevoegen. Er zijn nu contributors die Pull Requests openen om foutmeldingen toe te voegen aan onduidelijke fouten in de python-interpreter. Disclaimer: we moeten je pull request misschien afwijzen omdat het Python instabiel maakt of veel bijwerkingen veroorzaakt. De moraal van het verhaal is dat je van onduidelijke foutmeldingen kunt komen tot het twee jaar besteden om Python core developer te worden en de foutmeldingen te verbeteren, terwijl je een PhD doet.
Codebeez-reactie: Ik ben enthousiast over deze verbeteringen in Python 3.11; ik heb behoorlijk wat tijd verloren met onduidelijke foutmeldingen van de Python-interpreter. Precies die soorten fouten zijn verbeterd door het werk in deze talk. Dank aan alle betrokken Python core developers.
Python & Visual Studio Code - Revolutionizing the way you do data science
spreker: Jeffrey Mew (product manager bij Microsoft)
We zijn later begonnen vanwege technische problemen. Jeffrey werkt bij Microsoft en wil ons laten zien hoe Python + VScode de manier waarop je Data Science doet kan revolutioneren. We beginnen met een demoproject over salarissen en vaardigheidsniveaus om het verwachte salaris in tech te voorspellen. We splitsen het op in data-exploratie/cleaning, model training en productionalisatie. Er zijn features in visual studio code om het saaie werk te verbeteren. Laten we kijken naar data-exploratie, voor de stackoverflow survey-dataset. We hebben een VSCode-extensie voor Python nodig, die de notebook-functionaliteit bevat. We lopen door de notebook terwijl we de data inlezen en bekijken. Een van de grootste nadelen van een notebook is de variabele state die lastig te beheren is; we hebben een jupyter:variables-tab die onze variabelen toont. We hebben enkele ideeën in de maak voor variabele dependency management, maar nog niets bevestigd.
Introductie van data wrangler
Wanneer we naar een groot aantal kolommen kijken, kapt jupyter de kolomweergave af. Dit is onhandig omdat de output in een cel moet passen. Om dit te verbeteren hebben we momenteel enkele niet-interactieve views in VSCode. Ik introduceer Data Wrangler, een UI voor data cleaning in VSCode, die nog niet is uitgebracht. Data Wrangler is een gratis data cleaning- en verwerkingstool die zijn werk op de achtergrond doet. Dit is de eerste publieke showcase ervan; we werken er al een tijdje aan. We krijgen een data-overzicht met kolominfo en een contextmenu met bewerkingen op de data. Zoals het filteren van de data. Data wrangler zou de kolommen markeren die het zou filteren en genereert een pandas-statement waarmee we code als onze single source of truth kunnen behouden. Elke bewerking wordt gegenereerd in een aparte jupyter notebook-cel, wat de stappen reproduceerbaar en geïsoleerd maakt. Wanneer we klaar zijn, klikken we op export code to notebook, wat de verschillende stappen combineert tot een functie die een dataframe accepteert en gecleande data teruggeeft. Er is wat basale datavisualisatie aanwezig in Data wrangler die je gratis krijgt. Bijvoorbeeld om uitschieters in de data in een histogram te tonen. Dit in combinatie met de UI-gedreven data cleaning zou de snelheid van het data science-werk kunnen verhogen, aangezien 80% van de tijd wordt besteed aan data-exploratie/cleaning.
Protocols in Python: Why You Need Them
spreker: Rogier van der Geer
TOC
- Dynamic / static typeing
- type hints
- ABCs
- Protocols
1, Python is een dynamisch getypeerde taal, wat betekent dat? Types worden tijdens runtime gecontroleerd, typedeclaraties zijn niet vereist. Dit in tegenstelling tot statisch getypeerde talen. Het concept van duck typing wordt geïllustreerd met het klassieke voorbeeld van classes die onderling uitwisselbaar zijn zolang ze een minimale set vereiste methoden ondersteunen.
2, Optionele statische typering, die gecombineerd kan worden met mypy voor statische typechecking en runtime-fouten. We illustreren dit door een algemene “eat_bread”-functie te construeren die een argument accepteert met een typehint die een Duck is, of een Union van een Duck en Pig. Het laat zien dat we ruwweg generieke functies kunnen maken die compatibel zouden kunnen zijn met een gespecificeerde set types, wat door mypy gecontroleerd kan worden. Maar wat als we deze functie generiek willen maken, zonder elk acceptabel input-parametertype te specificeren.
3, Abstract base classes kunnen een blauwdruk definiëren voor alle dieren die kunnen lopen, passend bij ons voorbeeld. We kunnen al onze specifieke dierenclasses laten erven van onze abstract base class (ABC) voor dieren, wat een vereiste is omdat een ABC-class niet rechtstreeks gebruikt kan worden. ABC-classes zijn niet makkelijk bloot te stellen vanuit een library die je importeert. Het werkt echter wel om een set vereiste methoden te definiëren die NotImplementedError opwerpen, wat een implementatie in elke subclass vereist. Het blijft lastig om gemeenschappelijke ABC-classes over verschillende python-packages heen te beheren. Hoewel je dit kunt registreren met de ABC.register-methode, wat een beetje hacky aanvoelt door de indirectie en het monkey-patch-karakter.
4, Protocols lost onze uitdagingen rond het implementeren van generiek gedrag eleganter op. Een class die erft van Protocol definieert methoden en attributen die vereist zijn om als instance van die class te worden gezien. Elke class die minstens de methoden en attributen definieert die overeenkomen met de protocol-subclass, wordt beschouwd als subType van Eatsbread. Tijdens runtime respecteren instance-checks op objecten deze impliciete subtypering niet, althans niet zonder het toevoegen van de runtime_checkable-decorators. Protocols gedragen zich als ABC-classes omdat ze niet geïnstantieerd kunnen worden en geen deel uitmaken van de super()-keten van runtime-overervingsbeheer. Ik hoop dat ik je ervan heb overtuigd dat we protocols nodig hebben.
Event-driven microservices with Python and Apache Kafka
spreker: Dave Klein (confluent.io)
We richten ons op event state transfer waarbij het event een payload heeft en we ze messages kunnen noemen. Deze aanpak is waardevol voor het bouwen van microservices. Confluence omvat de oprichters van kafka, daarom leggen we de basiswerking van kafka uit. events hebben een key en een body in bytes, bevat doorgaans json- of avro-data. De events worden weggeschreven naar lineaire logs genaamd kafka topics, die bestaan uit partitions. Elke partition heeft een geordende set events, maar de volgorde is niet consistent over partitions heen. De producer schrijft de events naar de log met twee belangrijke libraries voor Python: kafka-python, confluent-kafka-python. De consumer leest events uit de topics. De producer en consumer coördineren niet. Het is de consumer die een offset bijhoudt om te weten waar hij was tijdens herstarts. Een schema registry bevat schemas die coördineren welke data verwacht en geschreven moet worden door consumer en producer. Consumer groups kunnen de offset beheren voor een set consumers, zodat elke applicatie-instance unieke events krijgt.
kafka event processing wordt voorgesteld als een alternatief voor een mesh van http REST-microservices om de architectuur schoner te houden. Beide benaderingen kunnen door elkaar gebruikt worden. consumers kunnen worden toegevoegd zonder andere consumers te beïnvloeden, zolang ze hun eigen index (consumer group) bijhouden.
What happens when you import a module?
spreker: Reuven M. Lerner
We schrijven pseudocode die overeenkomt met het importgedrag van Python. Imports wijzen het geïmporteerde toe aan globale variabelen. Een inzicht is dat een gedeeltelijke import niet betekent dat we de basismodule niet importeren.
from random import randint # it imports random fully, but does not assign it to a global
Python-globals leven alleen op moduleniveau. Modules worden geïmporteerd door elke regel uit te voeren; dit heeft implicaties voor wat zinvol is om in een module te schrijven. In die zin laadt Python een module niet, maar voert het deze uit.
Working with Audio in Python (feat. Pedalboard)
spreker: Peter Sobot (Spotify)
Digitale audio is een stroom van floating point-getallen (uncompressed 64bit floats, 21 Mb / min). Uncompressed fixed point (rond 10 Mb / min). Gecomprimeerde audio gaat omlaag naar rond 1Mb / min, maar dit vereist online decoding voor verwerking.
Audio lezen en bewerken met Python met Pedalboard.
from pedalboard.io import AudioFile
with AudioFile("my_favourite_song.mp3") as f:
print(f.samplerate)
f.read(3) # read 3 samples
De shape van de teruggegeven array is (2, 3) voor stereogeluid. Array slicing-syntax kan voor deze audio-arrays gebruikt worden. Numerieke indexen betekenen niet veel voor audio; we moeten f.samplerate gebruiken om tijdsbereiken te selecteren. We werken aan een slapback delay. We berekenen een delay x op basis van tijd maal samplerate. We itereren over onze array en tellen samples op van x samples terug maal een volumefactor (om onze audio niet te clippen). Dit kan ook begrepen worden als het optellen van twee arrays waarbij één array x samples naar voren is geschoven. Ik weet niet zeker waarom de presentator voorbeelden gaf met for-loops voor het manipuleren van arrays.
Audio kan groot zijn in het geheugen na decoding. Een basale aanpak is om de audio in chunks op te delen zodra deze binnenkomt en te verwerken. Lijkt een goede fit voor een generator, hoewel de spreker een while-loop laat zien. Python is traag, daarom bestaan numpy en pedalboard, die operaties in c uitvoeren, gemapt over arrays die in het geheugen zijn geoptimaliseerd.
VST-plugins kunnen met Pedalboard worden geladen om ze toe te passen op audio vanuit Python. Streaming-ondersteuning bestaat als pull request en zou enkele beperkte integraties met andere audiosoftware mogelijk kunnen maken.
Dag 2
PyArrow and the future of data analytics
spreker: Alessandro Molina
PyArrow implementeert 90% van wat beschikbaar is in Arrow zelf. De PyArrow Array lijkt op een Numpy array, zonder conversiekosten tussen de twee. De array ondersteunt geneste datatypes inclusief alle data, niet via referenties naar de python-objecten zoals dictionaries. Dit ontbreken van referenties vergroot de kans op computationele optimalisatie in het geheugen, vooral gevectoriseerde operaties. Elke waarde kan worden gedefinieerd als een ontbrekende waarde, met een validity map. We zijn dus gegarandeerd van één enkele continue geheugenbuffer met alle waarden, wat computationele optimalisatie vergroot.
Naast datarepresentatie ondersteunt pyarrow ook operaties om data te manipuleren. Voorbeelden zijn element-wise vermenigvuldiging van arrays als expliciete functieaanroep. We overwegen syntactic sugar te ondersteunen vergelijkbaar met numpy, maar voorlopig hebben we expliciete functies voor manipulaties.
import pyarrow as pa
arr = pa.array([1, 2, 3, 4, 5])
pa.multiply(arr, 2)
PyArrow Tables
Arrow is geboren als een columnar format. Tables bestaan eigenlijk uit pyarrow.chunkedArray, zodat het toevoegen van rijen eraan een goedkope operatie is. Hier lijkt PyArrow op pandas DataFrames. Appends beïnvloeden de huidige memory layout niet, wat optimaler is dan een pandas dataframe dat bij appends volledig gekopieerd moet worden. De Acero compute engine ondersteunt veel dataframe-gerelateerde operaties zoals joinen, filteren en aggregeren. PyArrow tables hebben een schema met een type per kolom dat opgebouwd kan worden uit pyarrow arrays of python lists met een lijst van kolomnamen.
Als je al numpy of pandas gebruikt, dan kun je makkelijk overstappen naar pyarrow met de zero copy data-conversies die worden geboden. Het ontwerpdoel was om interoperabiliteit te ondersteunen zonder conversie-overhead. Veel systemen ondersteunen arrow, waarbij Spark, pandas en numpy het meest relevant zijn. Dataconversie is handig, maar het kan de moeite waard zijn om ook de pyarrow compute engine direct te gebruiken. Het is vaak sneller dan de pandas- of numpy-operaties. Naast pyarrow direct te gebruiken kunnen we het ook als expliciete backend voor pandas gebruiken bij het inlezen van data.
pd.read_csv("example.csv", engine="pyarrow")
Laziness met PyArrow Datasets.
Pyarrow biedt Datasets met lazy access om te voorkomen dat alles in één keer in het geheugen geladen moet worden. Datasets worden in de meeste gevallen ondersteund door de Acero compute engine, in plaats van tables. De Dataset API combineert file formats, verschillende filesystems (local, cloud) met een DataFrame API en een query engine. PyArrow beheert veel van het laden van data van meerdere bestanden in partitions. De API voor datasets is een subset van de tables-API, maar ondersteunt wel enkele kern-operaties zoals filtering, projecting en joining. Conversie naar Tables is mogelijk om de volledige API te krijgen. PyArrow biedt meer, zoals Arrow Flight dat data-uitwisseling tussen client en servers beheert. Data writers om data te dumpen naar verschillende bestands- en messageformaten.
Scaling scikit-learn: introducing new sets of computational routines
spreker: Julien Jerphanion
Nieuwe sets computational routines voor scikit-learn, ontwikkeld door het bedrijf waar scikit-learn vandaan komt. We willen verbeteren wat er bestaat, in plaats van glimmende nieuwe features toe te voegen. Een van de verbeteringen is performance. Er is een performancegat met andere cutting edge machine learning-libraries. De focus is om de kernoperaties in scikit-learn te verbeteren, zodat een brede set library-methoden van de snelheidsverbetering profiteert.
Het geval van k-nearest-neighbors met de brute force-aanpak. Het partitioneren van een matrix rond de kth smallest value (pivot). Dit wordt in numpy gedaan met nap.argpartition, np.argsort. Dit zal je computer laten crashen omdat het niet in het RAM past. Dus we kunnen sets van vectoren maken en onze operaties parallel vectoriseren met joblib. Veel van de overheadkosten in deze parallelle operatie zijn de PyObject-conversies en de GIL. De chunking-strategie is suboptimaal omdat deze tijdelijke arrays creëert die extra kosten met zich meebrengen. Python is een beetje vereenvoudigd, het mist ingebouwde ondersteuning voor diverse gedistribueerde commando’s. We omzeilen de GIL met cython, zolang we onze python annoteren met extra type-informatie.
Onze doelgroep gebruikt voornamelijk laptops om onze modellen te trainen. Die hebben CPU’s met meerdere cores, elk met dedicated cache-opslag op 3 lagen. We moeten de beweging tussen RAM en de buitenste L3-cache verminderen. Gecombineerd met low level-parallellisme met OpenMP (via Cython) en geoptimaliseerde lineaire-algebra-libraries zoals BLAS level 3-operaties. Met deze combinatie kunnen we ongeveer lineaire snelheidsverbeteringen krijgen naarmate het aantal cores (threads) toeneemt. Bij een hoog aantal cores verliezen we wat voordeel aan overhead.
Hoe kunnen we elk van onze verbeteringen meten. We gebruiken perf, waarmee we onze oplossing kunnen profileren in CPU-cycles per operatie. Als we kijken naar de tijd die in de kernoperatie wordt besteed, gaat de meeste tijd naar vectorisatie waarbij we dezelfde operaties op meerdere floats tegelijk toepassen, wat laat zien dat de oplossing efficiënt is. Wanneer we naar de cache hits en misses kijken. Zien we veel meer cache hits, wat laat zien dat we geen onnodige swaps van data tussen RAM en L3-cache doen.
De chunking-aanpak kan worden toegepast op diverse scikit-learn-functionaliteit die dan profiteert van de parallellisatie. Onze library is georganiseerd als een hiërarchie van classes waarbij we de voordelen van optimalisaties van parent classes delen met alle subclasses. Toekomstig werk is hardware-specifieke computational routines die uitgebreid kunnen worden naar verschillende hardware-setups, ter ondersteuning van diverse hardwareleveranciers met een open design.
Hoe debug je? Print statements :) Duck debugging, praat tegen de eend en leg je code uit. Pysnooper uit een talk van gisteren kan je print statements verbeteren. Natuurlijk kunnen we debuggers gebruiken zoals pdb. We moeten door onze code heen stappen tot we de regel vinden die onze fout veroorzaakt.
In Python schrijven we asynchrone applicaties met asyncio die een eventloop draaien. ayncio biedt ons een debug mode, voor 1 het vinden van niet-awaited coroutines, 2 veel niet-threadsafe ayncio-API en meer. We kunnen de debug mode inschakelen via een environment-variabele, het meegeven van een cmd-parameter, of de eventloop aanroepen met debug true. Debug mode is uitgebreid en print updates van de eventloop, en je kunt een threshold instellen om coroutine-uitvoeringsduur te filteren.
Debugging asynchronous programs in Python
spreker: Andrii Soldatenko
Python is een geïnterpreteerde taal met een REPL voor interactief programmeren. Het probleem is dat je momenteel geen asyncio await binnen de REPL kunt gebruiken; het is een bekend probleem. De fix is gemerged om een alternatieve REPL te bieden die asyncio await ondersteunt. De IPython REPL heeft deze feature al met enkele hacks en ondersteunt await. Als je jupyter gebruikt, geldt dit ook, aangezien het onderliggend de ipython-kernel gebruikt en het zetten van breakpoints toevoegt.
debuggers, pdb definieert een interactieve debugger die reageert op het keyword “breakpoint()”. Hij pauzeert op het breakpoint en staat toe door de code en uitvoeringsstatus te stappen. pdb is vrij beperkt, dus we hebben pdbpp en ipdb. met rijke grafische interfaces. ipb ondersteunt het inhaken op het ingebouwde keyword breakpoint
export PYTHONBREAKPOINT="ipb.set_trace'
Het probleem is dat deze debuggers asyncio await niet ondersteunen. Asyncio staat niet toe dat de eventloop genest wordt. Wanneer je iets in de debugger wilt awaiten, wil je iets draaien bovenop een eventloop die al draait, en dat is niet toegestaan. Er is echter een workaround: als we pip install nest_asyncio doen, kunnen we een awaitable functie binnen de debugger uitvoeren door de huidige eventloop op te halen en deze tot voltooiing te draaien, met deze gepatchte nest_asyncio-eventloop.
Als we op Docker of kubernetes zitten, kun je altijd je asyncio-logging zien. We hebben aiomonitor, waar je via een http-poort verbinding mee maakt en die de logberichten met asyncio-tasks communiceert. Tenslotte hebben we aioconsole, een REPL-achtige die kan awaiten voor debugging.
Deadlocks zijn problematisch, waarbij twee coroutines elkaar nodig hebben om te eindigen. Dit kan out of memory crashen met een recursive error. Hoe kunnen we asyncio-deadlocks afhandelen? We kunnen een deadlock detector hebben, maar die hebben we niet in Python. De spreker laat wat code zien om deadlocks te doorbreken door tasks te cancellen die te lang duren.
awaitwhat kan je laten zien wat er momenteel actief is in de eventloop, met een keten van coroutines die je de keten van diverse dependencies toont om routines te vinden die vastzitten en buggy zijn.
aiodebug maakt callbacks mogelijk om te printen wanneer coroutines langer draaien dan een bepaalde threshold, die je kunt monitoren en in grafieken kunt weergeven voor productiedoeleinden
Dag 3
Jupyter - Under the Hood
spreker: Dhanshree Arora
Een notebook wordt opgeslagen als een JSON-map met arrays van cellen. de notebook client is verantwoordelijk voor het starten van de kernel en het communiceren hiervan met de notebook server. De server bevat veel functionaliteit die uitgebreid kan worden met plugins om met de notebook te interacteren. Communicatie loopt over het jupyter messaging protocol gebaseerd op ZMQ. Dit gestandaardiseerde protocol voorkwam dat mensen het wiel opnieuw uitvonden. Het ondersteunt een aantal socket types en patronen. Standaard request en reply gemapt op twee dedicated sockets. Dit patroon kan vastlopen in een receive-reply-cyclus en heeft geen fair queuing. Publisher-subscriber-model waarbij sockets topics vertegenwoordigen waarop je je kunt abonneren. Dealer- en Router-socketpatroon: de router en dealer kunnen messages ontvangen en doorsturen zonder ze te verwerken. De router kan zien wie luistert en kan fair queuing implementeren.
Jupyter heeft de publisher-subscriber- en de dealer-router-patronen nodig. dealer-router is in beide richtingen geïmplementeerd tussen client en server. De router in de ipython-kernel kan requests naar de frontend sturen en vice versa. Bijvoorbeeld een virtuele toetsenbordbinding die een prompt van de gebruiker vraagt. De normale richting is de frontend die de uitvoering van een cel van de kernel vraagt.
We kunnen programmatisch een notebook maken en het koppelen aan een kernel session met een http-request, dat de session start. Daarna kunnen we een AsyncKernelClient gebruiken om met de session te interacteren, om info te printen of er op verschillende manieren mee te interacteren. Dit is vooral gericht op custom session management. Kernels kunnen vooraf gedefinieerd worden met kernel specs in de lokale directory. Een willekeurig aantal sessions kan vanuit dezelfde kernel spec gestart worden. Normaal verbindt een notebook met één session, maar met het lagere niveau kun je execution requests naar verschillende kernels vanuit dezelfde notebook sturen. Het eco-systeem breidt nog steeds uit door dingen bovenop de basiscomponenten toe te voegen.
Why is it slow? Strategies for solving performance problems
spreker: Caleb Hattingh
Veel talks gaan over hoe je performance verbetert, maar niet veel talks gaan over hoe je performance diagnosticeert. 1) fundamenten waar we over moeten nadenken, 2) wanneer het makkelijk te draaien is, 3) wanneer code-uitvoering lastig is 4) gedistribueerde systemen.
1 fundamenten, Het is belangrijk te begrijpen waarom een systeem traag is. Je moet een goed overzicht hebben van wat het systeem doet terwijl een performanceprobleem wordt gevonden. We moeten uitvinden waarom het systeem traag is door verder te kijken dan specifieke regels code. Er zijn verschillende scenario’s tijdens de ontdekking: cache het, verwijder het, terwijl je voor grote verbeteringen gaat in plaats van micro-winsten. Hiervoor hebben we de call stack nodig om inspectie van het gedrag mogelijk te maken. Hiervoor hebben we tools nodig. Ik geef een korte lijst van wat ik op werk gebruik, gebaseerd op eenvoud en impact. We moeten de tools selecteren die ons de informatie geven die we nodig hebben, in dit geval de call stack.
2 Wanneer code-uitvoering makkelijk is (zoals lokale uitvoering) is het mogelijk om delen van het programma te draaien en dingen te herschikken tijdens tests. We kunnen unit tests schrijven specifiek om performanceproblemen te onderzoeken. de simpelste aanpak is Ctrl+C tijdens het draaien van het programma binnen een test. Dit geeft je een stack trace die bijna altijd hetzelfde is en kan aangeven waar het programma vastzit. Dit heet stack sampling. Dit lijkt te simpel om te werken, maar ervaring leert dat het erg effectief is. Vergeleken met cprofile kunnen we in beide de bottleneck zien, maar we kunnen de volgorde van de call stack niet zien in cprofile, wat in de Ctrl+C-stacktrace makkelijk te zien is. Cprofile is vrij duur en meet alles. De getallen in de output zijn zo gedetailleerd dat ze je ertoe kunnen brengen micro-verbeteringen te doen, in plaats van je ontwerp te heroverwegen. Pytest-profiling voegt een flag toe aan pytest om profiling in te schakelen —profile-svg. Deze svg toont een grafische kaart van je functieaanroepen met hun runtime-kosten in kleuren, verrijkt met statistieken. Het toont ook de relaties in de functie-call-stack als edges tussen de blokken in de figuur. Houd er rekening mee dat het veel duurder is vergeleken met Ctrl+C.
3 Py-spy is mijn magische keuze: een sampling profiler die in een productieomgeving gebruikt kan worden met een kleine performance-impact. Het kan stacktraces uit native extensions binnen je python-stacktrace opnemen. Het heeft een record-commando dat een svg-bestand dumpt en je toestaat subprocessen mee te nemen. Het geeft een zeer rijke grafische weergave van wat is aangeroepen met hun kosten. je kunt py-spy aan draaiende processen koppelen met top, dat een tabel van regels en hun run-statistieken teruggeeft. Het dump-commando is echt nuttig: het dumpt een lijst van alle call stacks voor zowel test- als productieprocessen, met informatie voor alle threads.
4 gedistribueerde systemen richten ons op de weinige opties die we hebben om performance te diagnosticeren. code naar believen draaien is erg lastig, en traagheid treedt misschien maar soms op op basis van zeldzame interacties. Toch geldt dezelfde regel: we willen een call stack die over gedistribueerde systemen heen werkt. We zouden idealiter willen dat deze geordend is op basis van de uitvoering. Distributed tracing is de naam voor onze vereisten. Er zijn veel vendors, waarvan we Honeycomb kiezen. De belangrijkste informatie uit een distributed trace zijn de temporele afhankelijkheden tussen systemen en hun runtime-kosten, waarbij het huidige systeem verandert naarmate we door de trace in de tijd naar beneden gaan. Hier zijn kosten aan verbonden, aangezien data continu verzameld moet worden en alle data naar een gecentraliseerde server overgebracht moet worden voor visualisatie. We moeten stukjes code aan elk van onze services toevoegen om de relevante traces naar onze tool te sturen.
Clean Architectures in Python
spreker: Leonardo Giordani (auteur van clean architecture in Python)
Ik wil mijn visie op systeemontwerp en mijn lessen delen. Wat is de definitie van architectuur? we noemen het vaak wanneer we over systemen praten. Vitruvius (15 v.Chr.) geeft aan dat het gaat over duurzaamheid, nut en schoonheid. Hoe vaak denken we over onze code in deze termen. We veranderen elke paar jaar van framework? is het mooi? wat mijn belangrijkste zorg is. Engineer komt van engines, maar engine komt van ingenuity (latijn), dus het gaat minder over mechanica en meer over het slim oplossen van problemen. Ik vond nog wat bronnen om architectuur te definiëren, die ik samenvoegde tot de kunst en wetenschap waarin de componenten van een computersysteem georganiseerd en geïntegreerd worden. hoe vaak denken we over ons werk als wetenschap en kunst? Wanneer kijk je naar je code en denk je aan kunst? waarom kan onze code niet mooi zijn? de organisatie van een systeem gaat over waar de componenten van het systeem zijn en hoe ze gerelateerd zijn. Hebben we het met deze definitie nodig?
Wanneer we een library maken, maken we dan alleen iets mechanisch, of maken we iets dat de ervaring beter maakt? Linux was goed ontworpen vanuit gebruikersperspectief en gebaseerd op Unix, 50 jaar geleden gemaakt. Ik sta er niet alleen in; ik toon een lijst van boeken die ik aanraad. De introducties van deze boeken geven je al een narratief om over na te denken bij het ontwerpen van systemen. Het is interessant dat message based-systemen en object oriented programming beide over messages gaan. OOP gaat over objecten die messages uitwisselen door elkaars methoden aan te roepen.
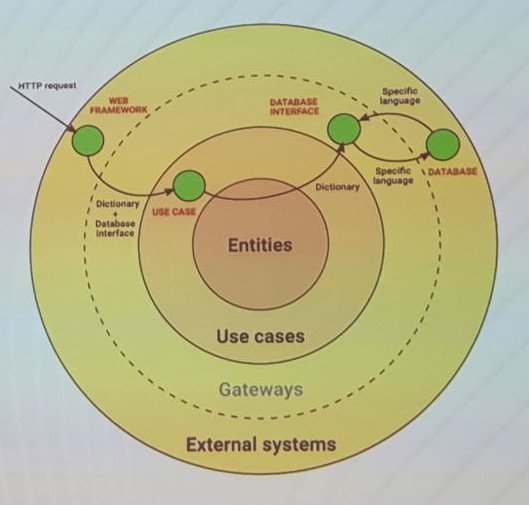
Dus wat is “clean” in clean architecture. Het is makkelijk om het tegenovergestelde van clean te definiëren: niet netjes, niet te onderhouden, spaghetti code. In een net systeem weten we waar wat en waarom het in het systeem zit. Clean architecture is layered architecture die door Robert Martin werd geïntroduceerd; hij praat over concepten die ouder zijn dan zijn werk. De gelaagde aanpak structureert software op een circulaire manier. Traditioneel hebben we vier lagen: External systems, Gateways, Use cases, Entities. Een component kan alleen definities in de binnenste lagen zien en communiceert naar binnen met simpele structuren (gedefinieerd in binnenste lagen) en naar buiten via interfaces (gedefinieerd in binnenste lagen). In Python hebben we protocols en ABC-classes om aan onze interface-behoeften te voldoen. Ons voorbeeld is simpel, het is valide Python, maar het is uitgekleed. De use case is het ophalen van een lijst van items. De functie die een item ophaalt, is gedefinieerd in de use cases-laag. Onze items zijn entities en gedefinieerd in de entities-laag. External systems vereist een web framework om een API bloot te stellen (hier flask), business logic is wat je vermarkt, de kern van je applicatie. Het web framework is geen deel van de business logic en kan in de external systems-laag leven. De kern-business logic leeft in de use cases-laag. We communiceren met simpele structuren, in ons geval een dictionary, wat dan ook beschikbaar is in de kerntaal. We moeten niet communiceren met iets dat gerelateerd is aan ons web framework of http-requests. Data wordt opgeslagen in een Data repository en kan een database-achtig systeem, een plat filesystem of een externe API zijn, enz. De data repository en de data repository-interface zijn implementatiedetail en geen deel van onze business logic. De use case mag niet rechtstreeks met de database communiceren, het zou er niet strak mee gekoppeld moeten zijn, dus we hebben de database-interface nodig die de specifieke kenmerken van de data repository abstraheert. De data repository-interface is een gateway en leeft in de gateway-laag. We gebruiken dependency injection om de database-interface in de use case-functionaliteit te injecteren, samen met onze simpele datastructuur. Tenslotte kunnen we het over onze business logic hebben. Uiteindelijk moeten we de request-parameters van het externe systeem doorgeven aan de database-interface die onze objecten als een lijst filtert. De business logic is misschien voornamelijk het opschonen van de request-parameters.
Secure Python ML: The Major Security Flaws in the ML Lifecycle (and how to avoid them)
spreker: Alejandro Saucedo
Deze talk is een oproep tot actie om de best practices te verkennen. Het is onmogelijk om systemen volledig veilig te maken, maar het is mogelijk om ongewenste uitkomsten te mitigeren. De technische oplossingen leunen nog steeds op mensen en zijn vatbaar voor social engineering. MLSecOps is een uitbreiding van DevOps en voegt extra security-vereisten toe bovenop wat met DevOps vereist is. We strooien de machine learning en complexe dataflows bovenop de typische complexiteit van IT-systemen. Uitdagingen gaan over reproduceerbaarheid, stabiliteit en consistentie. We mappen het klassieke OWASP top 10-concept op onze machine learning-oplossingen. Deze talk gaat niet specifiek over machine learning-deployment, maar we gaan een machine learning-model trainen, packagen, deployen/infereren.
We gebruiken MLServer gebaseerd op FastAPI met een scikit-learn-model op de IRIS-dataset (LogisticRegression). We persisteren ons model met joblib en kijken in dit binary om de bekende header te zien die de module beschrijft die we moeten laden om het model te instantiëren. We deployen dit model achter een API. Eigenlijk begint veel van het werk na de deployment, wanneer de lifecycle begint. Elke stap van de lifecycle is vatbaar voor hacks, dus we moeten beslissen wat high impact-issues zijn. Wat dubbele content over security-zorgen rond het gebruik van pickle voor model-serialisatie. Wat moeten we doen? Best practice is een zero trust-architectuur hebben. Als de aanvaller toegang tot de modellen heeft, kunnen ze diverse diepere aanvallen doen om de model-output te manipuleren. Bijvoorbeeld adversarial modelling om uitzonderlijke output uit het model te introduceren en het origineel te vervangen. Dependencies kunnen risico’s hebben in hun supply chains, omdat het lastig is om eerste-, tweede- of derde-orde-dependencies te verifiëren. Poetry staat je toe lockfiles te gebruiken, maar deze worden niet altijd gerespecteerd, zoals python wheels. We kunnen scans doen op Python-dependencies en docker images. Dit soort risico’s strekt zich uit tot in de onderliggende runtime, zoals kubernetes.
We hebben een EthicalML/sml-security cookiecutter op github gemaakt om mensen een goede start te geven met de security-posture van een machine learning-project. Het basisproject heeft een base server, dependency package management, dependency scanner, model versioning.