AzureML PyTorch GPU-enabled compute target: lokale en remote omgevingen verenigen
Microsoft en Python Machine Learning, een moderne liefdesgeschiedenis, deel 2/2
In deel 1 hebben we een workflow opgezet rond een VSCode-devcontainer en de AzureML Python SDK. We sloten af met het draaien van een Python-script op onze AzureML remote compute target met minimale moeite. Dat betekende ook dat het grootste deel van de configuratie van de compute target standaard was en buiten onze controle viel. In deze blog duiken we in de AzureML Compute Target Environment; we configureren die zo dat hij een GPU-workload met PyTorch ondersteunt. We sluiten af met een voorstel om lokale ontwikkeling en remote omgevingen voor AzureML te verenigen.
1 Compute Target Environment
1.1 Docker-image management
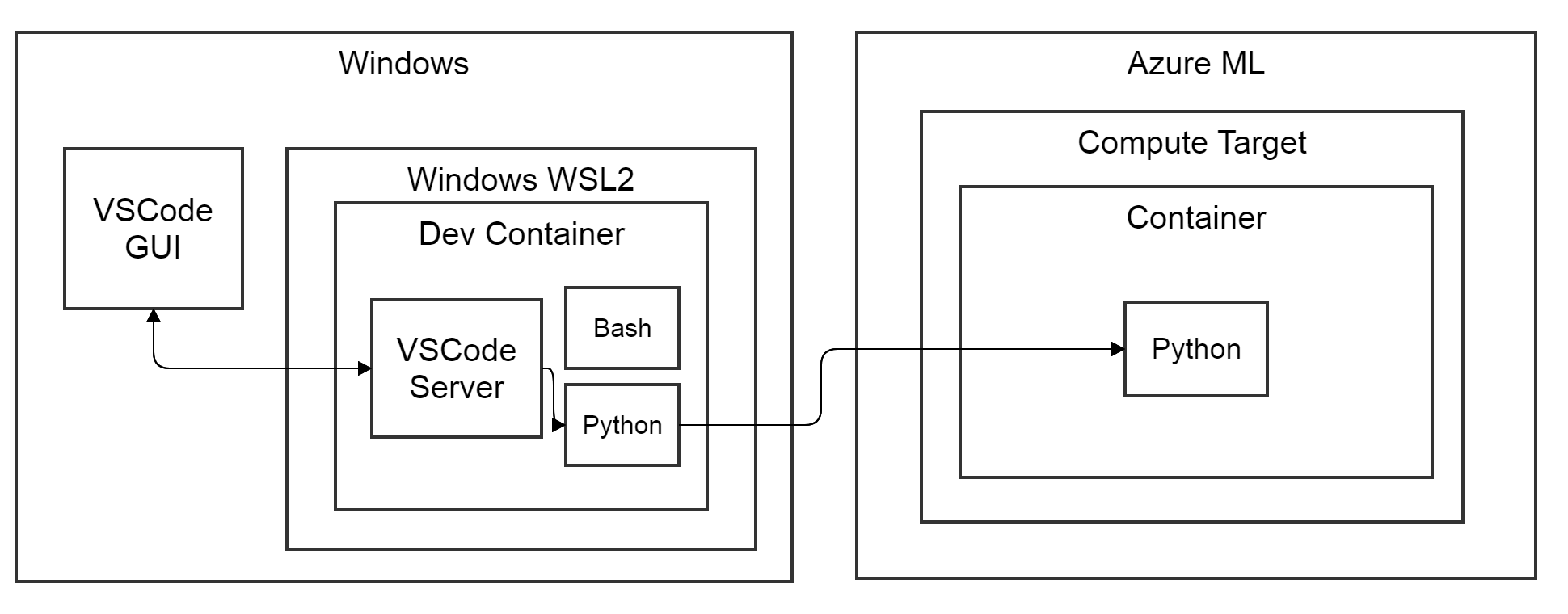
In het diagram hieronder zien we de Python-workload draaien binnen een remote docker-container op de compute target. Als we een CPU-cluster aanmaken en niets anders opgeven dan een RunConfiguration die naar de compute target wijst (zie deel 1), dan kiest AzureML bij de eerste run een CPU base docker-image (https://github.com/Azure/AzureML-Containers). Bovenop de base image wordt een conda environment aangemaakt en worden standaard python-dependencies geïnstalleerd om een AzureML-SDK-enabled Python-runtime te creëren. Nadat de image is gebouwd, wordt deze gepusht naar de docker-repository die aan je AzureML-workspace gekoppeld is, met een willekeurige UUID in de naam (patroon: azureml/azureml_
1.2 Environment class
De Environment class is een samenstelling van diverse classes die environmentvariabelen, programmeertalen, computing-frameworks en Docker configureren. De Environment bestaat uit secties voor Docker, Python, R en Spark. De PythonSection biedt bijvoorbeeld meerdere methoden om een Python-environment te creëren vanuit een bestaande conda environment, een conda-specificatiebestand, een pip requirements-bestand of programmatisch toegevoegde dependencies. De AzureML-environments kunnen in de workspace geregistreerd worden voor later gebruik. Het doel is om “reusable environments for training and deploying with AzureML” te maken (docs.microsoft/how-to-use-environments). In onze DIY MLOps zou dit analoog zijn aan het zippen van je volledige conda virtualenv en het uploaden ervan naar een artifactory voor latere deployment. Het detailniveau van de MLOps-API in de Python SDK is indrukwekkend, en hun recente verschuiving naar environment-gedreven configuratie biedt transparantie en flexibiliteit voor de gebruiker.
We richten ons op de Docker- en Python-secties.
- DockerSection, configureert de runtime docker-image en de container build- en run-parameters
- base_image, volledige docker-imagenaam met tags om de runtime-environment mee te bouwen
- base_image_registry, ContainerRegistry waar de base image zich bevindt. Standaard de MCR (Microsoft Container Registry)
- enabled, Boolean om docker in te schakelen, die in remote compute_targets genegeerd lijkt te worden en op True wordt geforceerd
- gpu_support, Deze boolean-property is deprecated, omdat hij nu autodetected wordt. Daarover later meer.
- arguments, extra argumenten voor het Docker run-commando. Mooi om zo veel kracht in handen van de AzurML-gebruiker te zien
- PythonSection, configureert de runtime Python-interpreter en zijn dependencies
- conda_dependencies, pip- en conda-dependencies die programmatisch zijn toegevoegd
- conda_dependencies_file, pip- en conda-dependencies vanuit een bestaand bestand.
- interpreter_path, pad naar de Python-interpreter, als je je eigen reeds bestaande Python-interpreter wilt gebruiken
2 PyTorch trainen op een GPU met AzureML
Om Deep Learning te gebruiken voor tekstclassificatie wilden we de nieuwste RoBERTa PyTorch-incarnatie trainen op een GPU-aangedreven compute target. AzureML biedt een reeks VM’s met GPU-ondersteuning (VM-sizes-gpu). Een instapformaat is de “NC6_standard”, die toegang heeft tot de helft van een k80-kaart wat telt voor 1 GPU (nc-series). Door dit formaat te selecteren voor onze AMLCompute class wordt de GPU-ondersteuning ingeschakeld door onze containers met “nvidea_docker” te draaien in plaats van de standaard docker engine. Deze auto-detectie is vrij nieuw en ik merkte dat hij bugged was voor losse compute-instances (msdn-post). Voor compute-clusters werkt de GPU-auto-detectie prima en daarom is de “gpu_support” Boolean op de Environment.DockerSection deprecated (azureml.core.environment.dockersection).
We creëren een runtime-environment die klaar is voor GPU-ondersteuning. We verwijzen naar deel 1 voor het aanmaken van een computing-cluster, wat ook de voorkeursmanier van werken is met slechts één VM. De enige wijziging ten opzichte van deel 1 is dat we het VM-formaat veranderen naar een GPU-ready formaat zoals de “NC6_standard”.
2.1 Een runtime PyTorch-environment met GPU-ondersteuning creëren
Voor onze doeleinden draaien we op Python 3.6 met Pytorch >=1.4.0 en cuda 10.1. Als base image nemen we een officiële AzureML-image, gebaseerd op Ubuntu 18.04 (AzureML-Containers/base/gpu), die native GPU-libraries en andere frameworks bevat. AzureML maakt bijvoorbeeld gedistribueerde training van deep learning-modellen mogelijk via het Horovod-framework (https://github.com/horovod/horovod), dat OpenMPI als communicatieprotocol tussen VM-nodes gebruikt. Op AMLCompute-clusters moeten we docker.enabled op onze Environment instellen, omdat het op True wordt geforceerd. Daarnaast wordt het gebruik van nvidea_docker boven de standaard docker engine auto-detected, dus het instellen van gpu.support op de Environment is eveneens overbodig.
Om de Python-packages in onze remote Conda-environment te beheren, manipuleren we een CondaDependencies-object en koppelen we het aan ons Environment-object. We roepen “add_conda_package” aan op dit object met een packagenaam en optionele versie en build. In het geval van PyTorch hadden we een specifieke build nodig om de GPU-backend in te schakelen. We moesten ook het “pytorch” conda-channel toevoegen met “add_channel” om deze packages te installeren. De programmatische aanpak van dependencybeheer beviel me in dit geval, hoewel je misschien de voorkeur geeft aan een conda- of pip requirements-bestand.

2.2 Een environment gebruiken voor een Estimator
2.2.1 Estimator class
Voor het trainen van ons PyTorch-model gebruiken we de Estimator class (azureml.train.estimator.estimator). De estimator kan worden ingediend bij een AzureML-experiment, dat hem op een compute target draait. Let op: voorgeconfigureerde estimators voor PyTorch, Tensorflow en SKLearn zijn deprecated sinds 2019-2020. Deze waren te impliciet over het configureren van de runtime-environment, waardoor ze inflexibel, moeilijk te onderhouden en magisch voor de gebruiker waren. Alle nieuwe gebruikers wordt aangeraden de vanilla Estimator class te gebruiken in combinatie met de Environment class.
De Estimator class heeft veel deprecated argumenten voor het aanmaken van een estimator-object. Hij ondersteunt zowel de deprecated impliciete API als de nieuwe Environment-gebaseerde configuratie. Daarom moeten we bijna alle parameters negeren bij het aanmaken van een estimator-object en ons alleen op het volgende richten.
- environment_configuration, hier geven we het Environment-object met onze runtime-configuratie door (zie sectie 1.2)
- compute_target, een referentie naar onze compute target, in ons geval een AMLCompute-object voor een remote compute-cluster
- source_directory, bepaalt welk deel van je lokale bestandssysteem naar de remote compute target wordt geüpload. Als je lokaal opgeslagen Python-modules gebruikt, moeten ze worden meegenomen om ze in je script te kunnen importeren.
- entry_script, een relatief pad naar je script binnen de “source_directory”.
- script_params, command line-argumenten die tijdens runtime aan ons “entry_script” worden doorgegeven. Een dictonary zoals {“—epochs”, 10}
2.2.2 Een estimator indienen bij een experiment
Om onze estimator binnen onze environment te draaien, moeten we hem indienen bij een experiment. Het experiment registreert alle runs binnen de AzureML-backend en verzamelt logging en output. Met de AzureML-SDK kunnen we ook onze modellen en datasets registreren (niet getoond). Hieronder maken we een estimator-object aan en geven we het ons environment-object door dat in settings.py is gedefinieerd. De compute target wordt opgehaald met de functionaliteit die in deel 1 is getoond. We maken een experiment aan of halen een bestaand experiment op onder de naam “test-estimator” en dienen onze estimator daar in voor een run.

3 Lokale ontwikkeling en remote training verenigen
Als we naar het diagram bovenaan deze blog kijken, zien we Docker-containers die zowel lokaal als remote draaien. Beide draaien delen van onze Python-code. Lokaal draaien we de code die ons AzureML-experiment en de estimator opstart. Remote draaien we onze model-trainingcode om ons model te trainen. Een van de beloften van Docker is het verenigen van de runtime-environment tussen ontwikkeling en productie. In diezelfde lijn willen we onze trainingcode lokaal debuggen tegen de environment die hij remote tegenkomt. Met andere woorden: we willen dezelfde Docker-image gebruiken voor lokale ontwikkeling en remote training van ons model. We kunnen de Docker-image die AzureML bouwt en naar onze workspace pusht lokaal pullen, door onze lokale docker te authenticeren met onze AzureML Docker-registry (container-registry-authentication). Dit authenticeren en pullen kan vereenvoudigd worden met de docker- en azure account-extensies voor VSCode. We nemen de gepullde Docker-image als basis voor een VSCode-devcontainer (zie ook deel 1) waarbinnen we onze code lokaal bewerken en draaien. Let op: we gaan voorbij aan de details van lokale GPU-ondersteuning en gaan ervan uit dat de ML-library terugvalt op GPU-compute voor lokaal testen.
3.1 Een devcontainer maken vanuit een AzureML compute target-image
Een VSCode-devcontainer vereist twee bestanden; een Dockerfile en een devcontainer.json binnen een “.devcontainer/“-map in ons project. De Dockerfile beschrijft onze Docker-image waaruit we een container bouwen. Het devcontainer.json-bestand is specifiek voor VSCode en configureert de integratie met de Docker-container, zoals het pad naar de Python-interpreter, de paden naar linting-executables, VSCode-extensies en bind mounts.
3.1.1 Dockerfile afgeleid van een AzureML-image
Binnen onze Dockerfile (zie hieronder) erven we van de base image in onze AzureML ContainerRepository. Lokaal willen we Python dev-dependencies zoals black, pylint en pytest in de container installeren. We installeren ze binnen dezelfde Python-environment die AzureML gebruikt om onze code te draaien, hoewel er andere keuzes gemaakt kunnen worden. Door AzureML gegenereerde Conda-environments bevinden zich in “/azureml-envs/” op de image. De naam van de Conda env bevat nog een willekeurige UUID met patroon: “azureml_

3.1.2 VSCode integreren met de container
Het devcontainer.json-bestand definieert onze integratie tussen VSCode en onze Docker-container. We definiëren een naam voor onze devcontainer, gevolgd door het pad naar onze Dockerfile (je kunt ook direct een image instellen). Gevolgd door de VSCode-settings met paden voor onze Python-interpreter en diverse devtools zoals black, pytest en pylint. We sluiten af met de VSCode-extensies die we binnen onze devcontainer willen installeren.

3.2 Samenvatting: AzureML-image devcontainer
Met de AzureML Environment class hebben we de runtime-configuratie van de remote compute target gedefinieerd op basis van een GPU-enabled docker-image. Deze environment werd door AzureML geconsolideerd als een custom docker-image die het naar zijn docker-registry pushte. We gebruikten deze custom image om een VSCode-devcontainer te maken die onze ontwikkel- en remote omgeving verenigt. Hierdoor kunnen we lokaal testen tegen dezelfde environment waarop we remote draaien. In deel 1 hadden we lokaal en remote verschillende containers (deel 1).
4 AzureML, een verenigde workflow
In deze tweedelige blog keken we naar een workflow voor AzureML met VSCode-devcontainers. We richtten ons op Windows als OS, maar de workflow werkt net zo goed voor Linux, zolang je distributie wordt ondersteund door de AzureML-SDK (specifiek de data-prep-dependency: data-prep-prerequisites). We zijn aangekomen bij een verenigde environment-configuratie van onze lokale ontwikkeling en remote compute target. Bedankt voor je aandacht en ik kijk ernaar uit te bloggen over meer onderwerpen rond Python, Machine Learning en Data engineering.
4.2 Mogelijke breekpunten bij het automatiseren van deze workflow
De twee willekeurige UUID’s die door AzureML worden gegenereerd bij het aanmaken van de Conda env bovenop de base image en in de naam van de Docker-repository zijn mogelijke breekpunten voor het automatiseren van deze workflow over teams en experimenten heen. De naam van de Docker-repository die door AzureML wordt gegenereerd, is te vinden in het logbestand “20_image_build_log.txt” van de experiment-run in de AzureML studio (https://ml.azure.com), in de interface van de docker-registry die aan de AzureML-workspace is gekoppeld op portal.azure.com of via de API ervan. Een lijst van Conda-environments op de image kan worden verkregen door het volgende commando uit te voeren.